
This is a question I get fairly regularly these days: Should we extract relational data and load it to a data lake?
Architecture diagrams, such as the one displayed here from Microsoft, frequently depict all types of data sources going thru the lake:
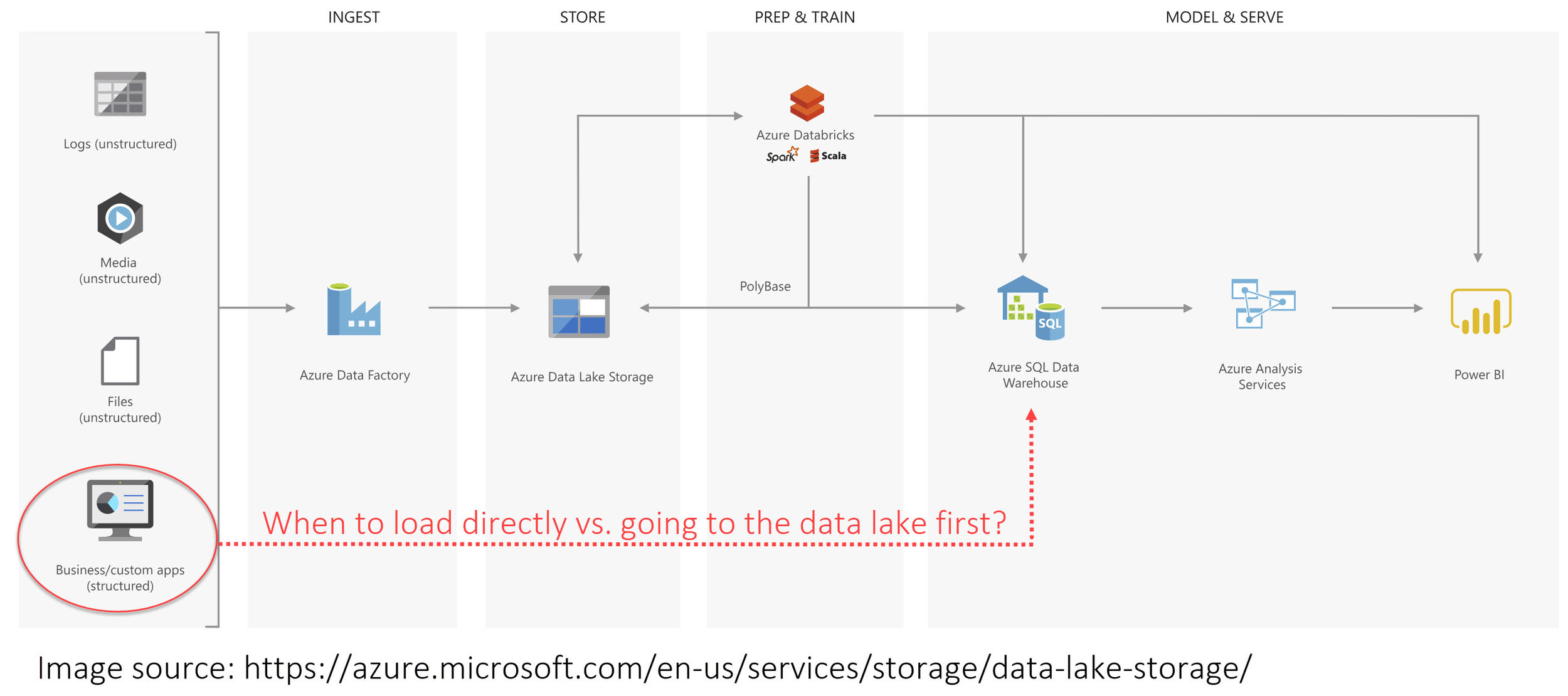
For certain types of data, writing it to the data lake really is frequently the best choice. This is often true for low latency IoT data, semi-structured data like logs, and varying structures such as social media data. However, the handling of structured data which originates from a relational database is much less clear.
Most data lake technologies store data as files (like csv, json, or parquet). This means that when we extract relational data into a file stored in a data lake, we lose valuable metadata from the database such as data types, constraints, foreign keys, etc. I tend to say that we "de-relationalize" data when we write it to a file in the data lake. If we're going to turn right around and load that data to a relational database destination, is it the right call to write it out to a file in the data lake as an intermediary step?
My current thinking is that this is justified primarily by these situations:
(1) Do you need to keep the history? If you are retaining snapshots as of periodic points in time, having those snapshots accessible in a data lake can be useful.
(2) Will multiple downstream teams, systems, or processes access the data? If there are multiple consumers of the data (and presumably we don't want them accessing the original source directly), then it's possible that providing data access from a data lake might be beneficial.
(3) Do you have a strategy of storing *all* of the organizational data in your data lake? If you've standardized on this type of approach, and (1) or (2) above applies, then it makes sense.
(4) Do you need to provide a subset of data for a specialized use case? If you can't provide access to the source database, but a full replica or another relational DB is overkill, then delivery of data via the data lake can sometimes make sense.

The above list isn’t exhaustive - it always depends. My rule of thumb: Avoid writing relational data to a data lake when it doesn't have value being there. This is an opinion and not everyone agrees with this. Even if we are using our data lake as a staging area for a data warehouse, my opinion is that all relational data doesn't necessarily have to make a pit stop in the data lake except when it's justified to do so.
You Might Also Like…
Data Lake Use Cases and Planning Considerations
James Serra’s blog - Should I load Structured Data Into My Data Lake?