
In this post, I will try to convince you that using SQL Server Data Tools (SSDT) Database Projects is a really good idea. Recently during a project I've been advocating that it indeed is worth the effort. Since I'm a BI architect, I'm framing this conversation around a data warehouse, but it certainly applies to any type of database.
What is a Database Project in SQL Server Data Tools (SSDT)?
A data warehouse contains numerous database objects such as tables, views, stored procedures, functions, and so forth. We are very accustomed to using SSDT BI projects (formerly BIDS) for SSIS (Integration Services), SSAS (Analysis Services), and SSRS (Reporting Services). However, it's a less common is using SSDT to store the DDL (data definition language) for database objects.
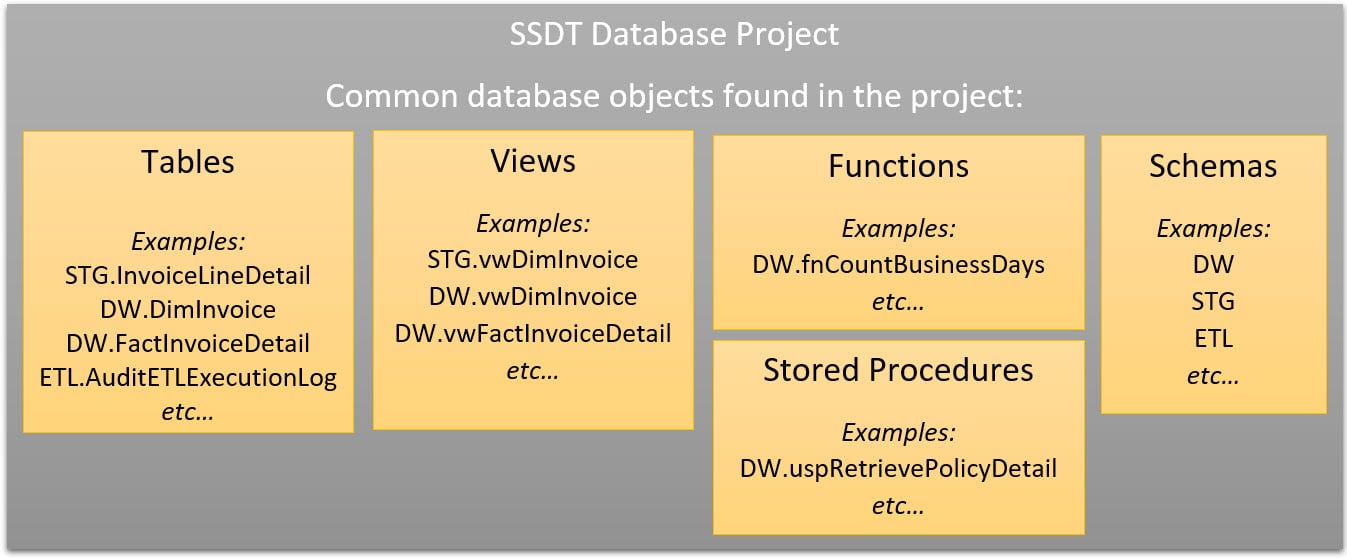
Below is an example of how you could structure your database project (am only showing a few tables and views in the screen shots for brevity). You don't have to structure it this way, but in this project it's sorted first by schema, then by object type (table, view, etc), then by object (table name and its DDL, etc).

The contents of items in the SSDT DB project are the 'Create Table' statements, 'Create View' statements, 'Create Schema' statements, and so forth. This is based upon “declarative database development” which focuses on the final state desired for an object. For instance, here's the start for a DimDate view:

Since the DimDate view resides in the DW schema, the database project would do me the favor of generating an error if the DW schema didn't already exist, like follows:

Team Foundation Server does integrate well with database projects (i.e., for storing scripts for database objects such as tables, views, and functions), Integration Services, Analysis Services, and Reporting Services.
There's an online mode as well as offline mode; personally I always use the project-oriented offline mode.
Now that we know about the structure of what's in a project, let's talk next about how we manage changes, such as an alter to add a new column.
Managing Changes To Database Objects
The next big thing to know is that there's a mechanism for managing DDL changes, for instance a new column or a change to a data type. Instead of putting an 'Alter Table' statement into the database project, instead you edit that original 'Create Table' statement which focuses on the final state that includes the new column.
Now let's say you are ready to promote that new column to Dev, QA, or Production. Here's where it gets fun. In the database project you can do a 'Schema Comparison' operation which will compare the DB objects between the project and the database. It will detect the difference and script out the necessary 'Alter Table' script to use in your deployment to Production.
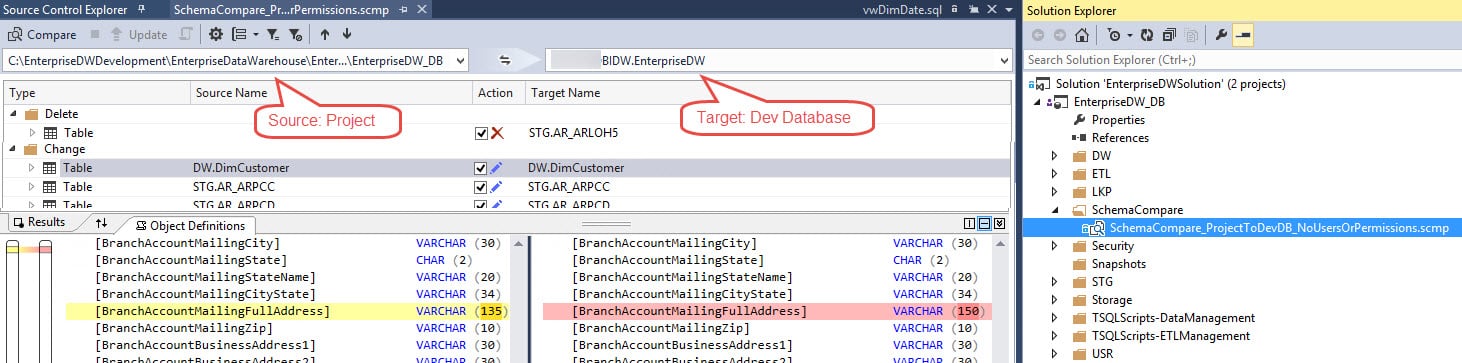
The output above tells us there's a data type difference between the project and the database for an address column. This helps us reconcile the differences, then we can generate a script which would have an Alter Table statement for the address column (though in the above case, the address is varchar(150) in the database which probably means the ETL developer widened the column but forgot to circle back to the database project - so there's still a lot of judgment when comparing the project to Dev).
Let's take this one step further. When we're ready to promote to a new environment, we can do a schema comparison between Dev and QA, or QA and Prod, and generate a script that'll contain all of the Creates and Alters that we need to sync up the environments. If you are envisioning how handy this is for deployment purposes, then I've already accomplished my mission. (Keep reading anyway though!)
There's a lot more to know about using schema compare, but let's move next to the benefits of using an SSDT database project.
Benefits of Using a Database Project in SQL Server Data Tools (SSDT)
DB projects serve the following benefits:
- Easy availability to DDL for all objects (tables, views, stored procedures, functions, etc) without having to script them out from the server and/or restore a backup. (See additional benefits in the next list if you also integrate with source control, which is highly recommended.)
- Functionality to script out schema comparison differences for the purpose of deployment between servers. If you've ever migrated an SSIS package change and then it errored because you forgot to deploy the corresponding table change, then you'll appreciate the schema comparison functionality (if you use it before all deployments that is).
- Excellent place for documentation of a database which is easier to see than in extended properties. For example, recently I added a comment at the top of my table DDL that explains why there's not a unique constraint in place for the table.
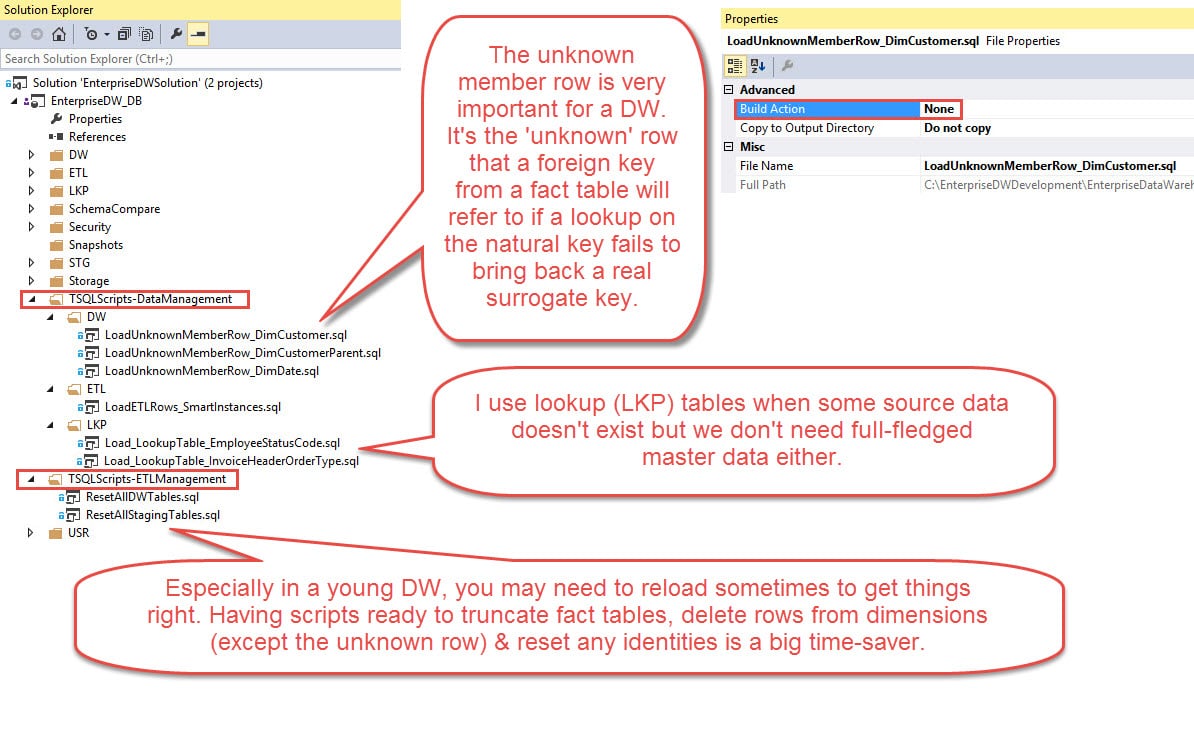
- Provides a location for relevant DML (data manipulation language) statements as well, such as the unknown member rows for a dimension table. Note: DML statements do need to be excluded from the build though because the database project really only understands DDL.
- Snapshot of DDL at a point in time. If you'd like, you can generate snapshot of the DDL as of a point in time, such as a major release.
Additional benefits *if* you're using a DB project also in conjunction with source control such as TFS:
- Versioning of changes made over time, with the capability to quickly revert to a previous version if an error has occurred or to retrieve a deleted object. Useful comments should be mandatory for all developers who are checking in changes, which provides an excellent history of who, when, and why a change was made. Changes can also be optionally integrated into project management processes (ex: associating a work item from the project plan to the checked-in changeset).
- Communicates to team (via check-outs) who is working on what actively which improves team effectiveness and potential impact on related database items.
Tips and Suggestions for Using a SSDT Database Project
Use Inline Syntax. To be really effective for table DDL, I think it really requires working -from- the DB project -to- the database which is a habit change if you're used to working directly in SSMS (Management Studio). To be fair, I still work in SSMS all the time, but I have SSMS and SSDT both open at the same time and I don't let SSDT get stale. The reason I think this is so important is related to inline syntax - if you end up wanting to generate DDL from SSMS in order to "catch up" your database project, it won't always be as clean as you want. Take the following for instance:
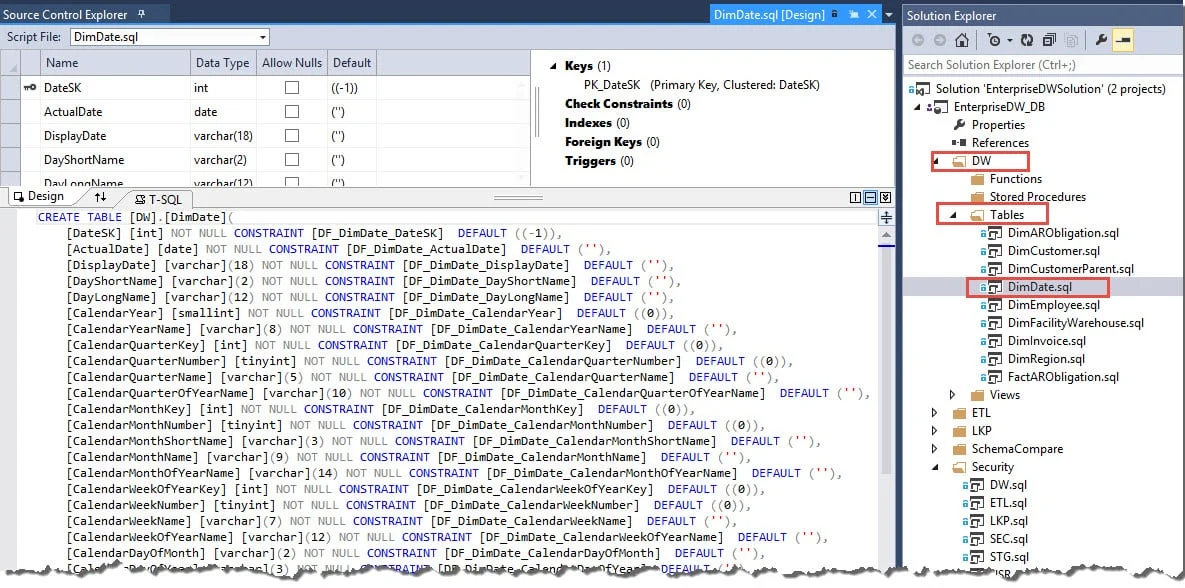
In the above script I've got some default constraints (which are named because who wants the ugly DB-generated constraint names for our defaults and our foreign keys and such, right?!?). The constraints are all inline -- nice and tidy to read. If you were to script out the table shown above from SSMS, it would generate Alter Table statements for each of the constraints. Except for very small tables, that becomes impossible to validate that the DDL is just how you want it to be. Therefore, I suggest using inline syntax so that your database project SQL statements are all clean and easy to read.
Store Relevant DML in the Project (Build = None). If you have some DML (data manipulation language) statements that are manually maintained and need to get promoted to another environment, that makes them an excellent candidate for being stored in the DB project. Since the database project only understands DDL when it builds the project, the 'Build' property for each DML SQL script will need to be set to None in order to avoid errors. A few examples:
Build the Project Frequently. You'll be unpopular with your coworkers if you check something in that doesn't build. So you'll want to develop the habit of doing a build frequently (around once a day if you're actively changing DB objects), and always right after you check anything in. You can find the build options if you right-click the project in Solution Explorer. Sometimes you'll want to choose Rebuild because then it’ll validate every object in the solution whether it changed or not (whereas the Build option only builds objects it detects changed, so although Rebuild takes longer it’s more thorough).

One more tip regarding the build - if a schema comparison operation thinks a table exists in the database but not in the project, check the build property. If it's set to None for an actual DDL object, then it will accidentally be ignored in the schema comparison operation. Bottom line: set all DDL objects to build, and any relevant DML to not build.
Do a Schema Comparison Frequently. Regularly running a schema compare is a good habit to be in so that there isn't a big cleanup effort right before it's time to deploy to another environment. Let's say I'm responsible for creating a new dimension. As soon as the SSIS package is done with the DDL for the table and views(s) as appropriate, I'll do a schema compare to make sure I caught everything. If your team is a well-oiled machine, then if you do see something in the schema comparison between the project and the Dev DB, it should be something that you or a coworker is actively working on.
Save the Schema Comparison (SCMP) Settings in Your Project. To make it quick and easy to use (and more likely your whole team will embrace using it), I like to save the schema comparison settings right in the project. You can have various SCMPs saved: Project to Dev DB, Dev DB to QA DB, QA DB to Prod DB, and so forth. It's a big time-saver because you'll want to tell the schema compare to ignore things like users, permissions, and roles because they almost always differ between environments. By saving the SCMP you can avoid the tedious un-checking of those items every single time you generate the comparison.
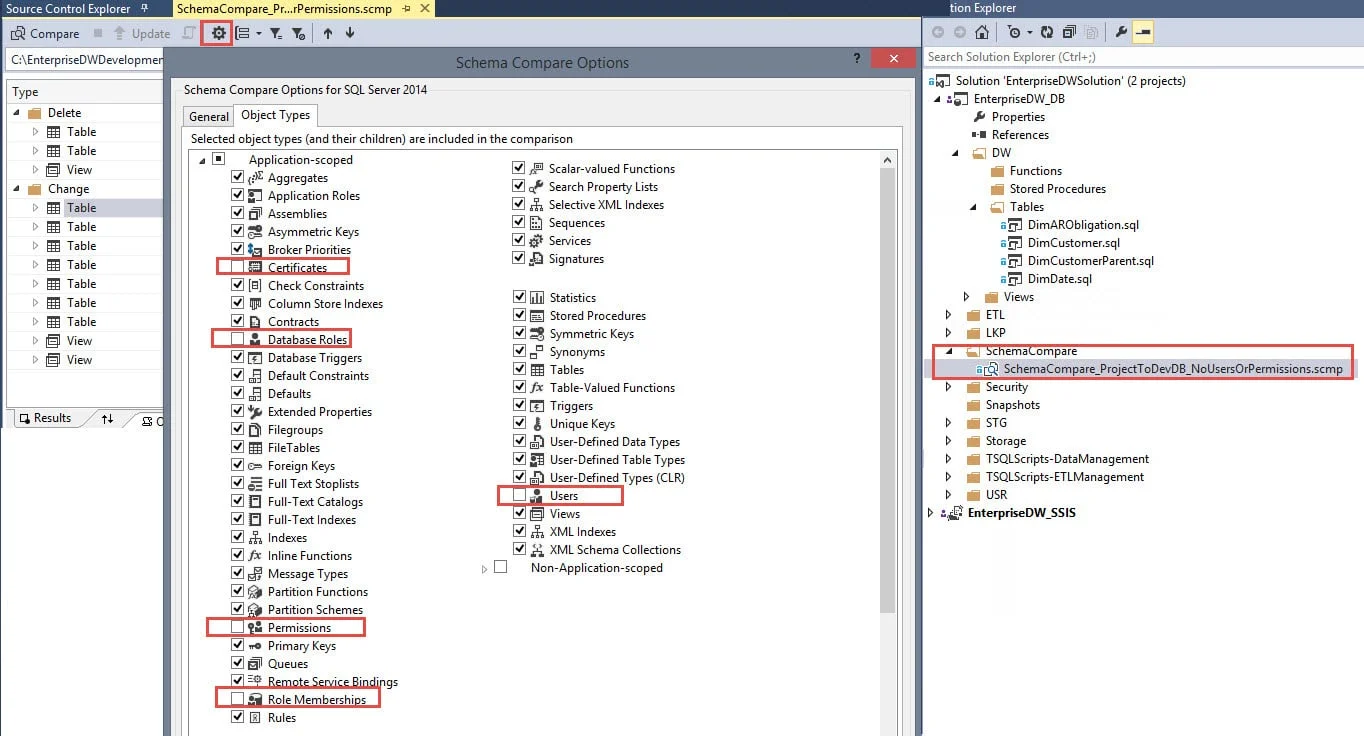
Do a 'Generate Script' for the Schema Comparison; Don't Routinely Use the Update Button. Just to the right of the Update button (which I wish were less prominent) is the Generate Script button. This will create the relevant Create and Alter statements that it detects are necessary based on the differences found. Scripting it out allows you to validate the script before it's executed, and to save the history of exactly what changes are being deployed when (assuming it's being done manually & you're not doing automated continuous deployments to Prod). I also prefer to generate the script over letting SSDT do a straight publish because items that are checked out are still part of a publish and we don't usually want that (though it does depend on how you handle your source control branching).

While we're on the subject of the scripts generated by the DB project: a couple of things to know. First, you'll need to run the script in SQLCMD mode (in SSMS, it's found on the Query menu). Second, the scripts are not always perfect. For simple changes, they work really well, but sometimes things get complicated and you need to 'manhandle' them. For instance, there might be data in a table and the script has a check statement in the beginning that prevents any changes and might need to be removed or handled differently.
Separate Installation for SSDT vs SSDT-BI Prior to SQL Server 2016. If you go to create a new project in SSDT and you don't see SQL Server Database Project as an option, that means you don't have the right 'flavor' of SSDT installed yet. Thankfully the tools are being unified in SQL Server 2016, but prior to that you'll need to do a separate installation. The SSDT installation files for Visual Studio 2013 can be found here: https://msdn.microsoft.com/en-us/library/mt204009.aspx.
There's a lot more to know about DB projects in SSDT, but I'll wrap up with this intro. There is a learning curve and some habit changes, but hopefully I've encouraged you to give database projects a try.
Finding More Information
Jamie Thomson's blog - 10 Days of SSDT
Jamie Thomson's blog - Considerations When Starting a New SSDT Project