This is just a quick tip re: updating metadata in SSIS. A few days ago I was speaking with an SSIS developer who wasn't aware of this change so I thought I'd share it.
Let's say a column is deleted in the underlying table or view that feeds an SSIS package. Or, maybe you're starting with a 'template' SSIS package that has metadata for a different table than the one you are building...once you adjust the source query, you see red X's on the precedence constraints (pipeline paths) in the data flow:
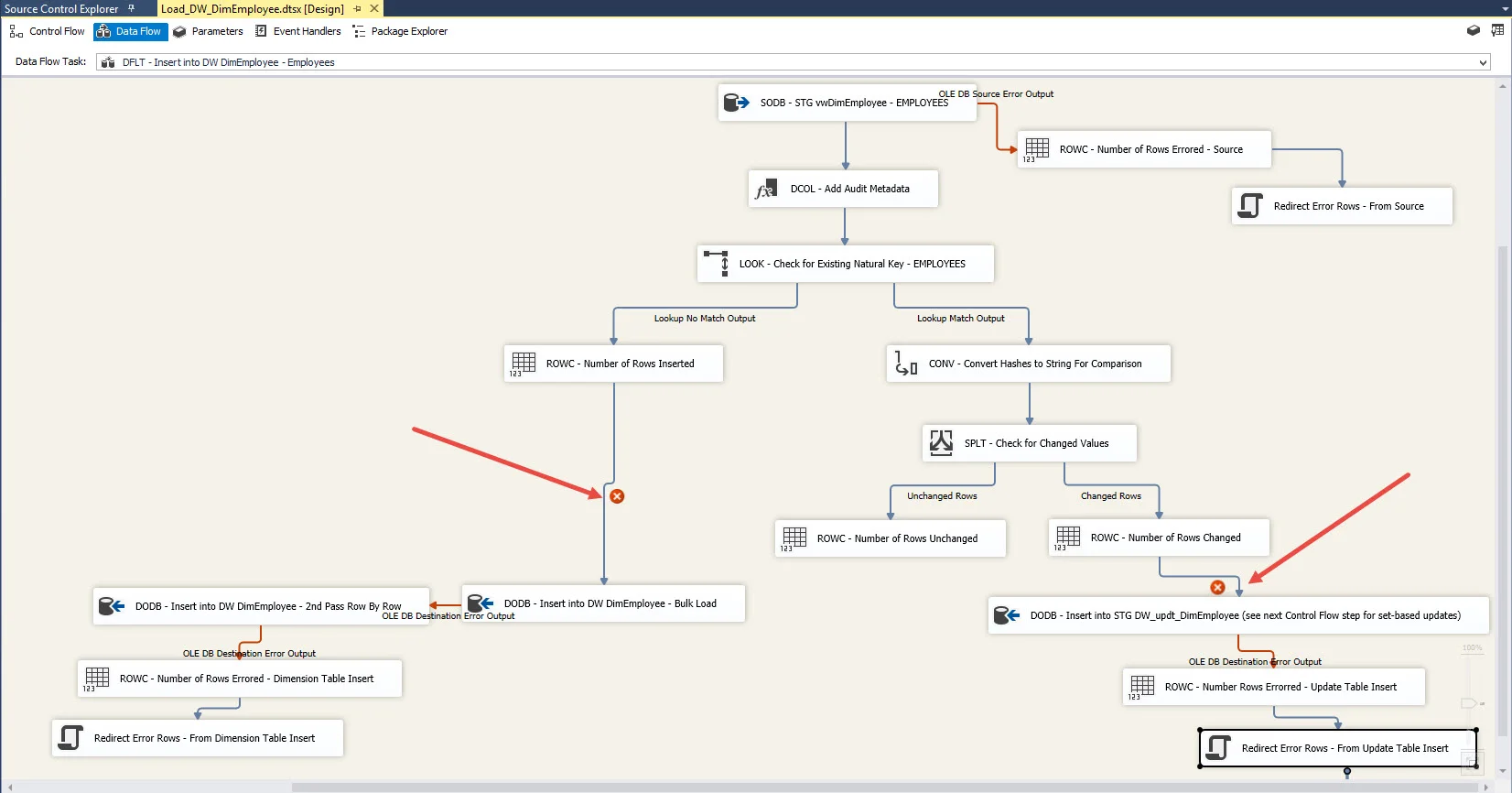
Prior to SQL Server 2012, updating metadata changes of this nature was a very tedious process. It's now *much* easier than it was before. First, you right-click on the precedence constraint and choose Resolve References:
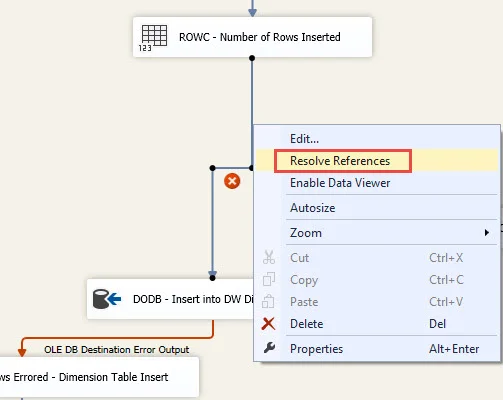
Then you want to check the box on the bottom left (it's not checked by default) then OK. It will then delete the downstream references in the package for the column(s) which no longer exist:

And voila, the references no longer exist for the transformations down below in the data flow. You might have to do this in a couple of places if the data flow splits off (like mine does in the screen shot). Depending on what else changed, you may also need to 'click through' some of the pages of some transformations to update metadata (ex: a data type change), but the Resolve References functionality is a huge time-saver.

My BlueGranite colleague and friend Meagan Longoria has been convincing me recently that these are the kind of changes that BIML is well-equipped to take care of quickly & efficiently when it regenerates a package. I will learn BIML soon (really I will, I will), but in the meantime, Resolve References sure is a handy thing to know. It certainly delighted the SSIS developer I was speaking with last week!
You Might Also Like...
Getting Started with Parameters, Variables & Configurations
Parameterizing Connections and Values at Runtime Using SSIS Environment Variables