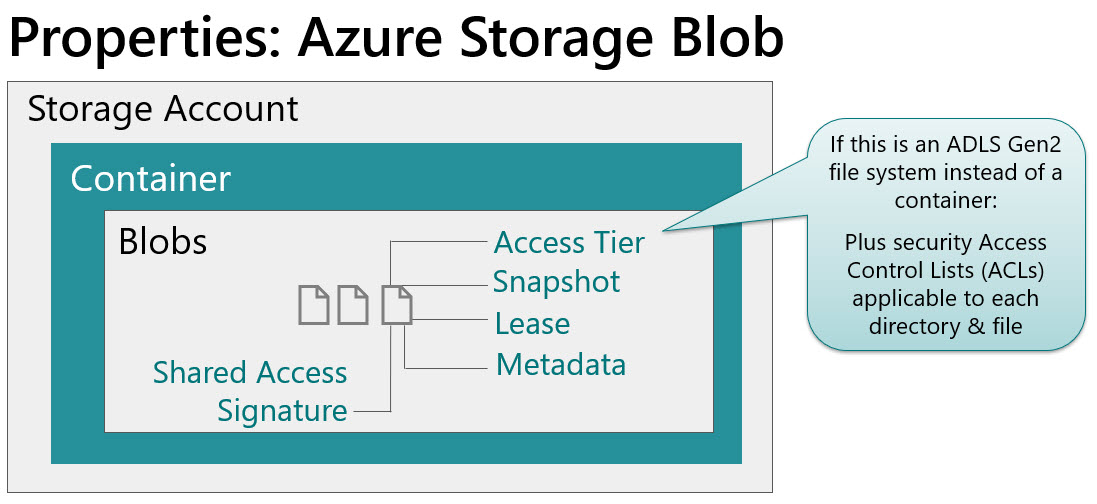
This post is to make you aware that there are some serious downsides when you choose to create reports in the Power BI Service rather than Power BI Desktop. If you agree with me on this one, please vote for this idea here on the Power BI Ideas site.
The Short Version of the Story
I always recommend to Power BI authors that report creation & editing should happen in Power BI Desktop and to just ignore the edit capability in the Power BI Service. Usually my reasons are concerned with:
Which version is the latest version (if both Desktop and the web are being used by one or more people)?
We’d like to have version history available (not available with the web but can be if you store the PBIX file on OneDrive for Business, SharePoint, or a source control repository).
Reducing the risk of someone overwriting someone else’s work because two different report editing/publishing options are in use.
These are very valid concerns, but I’ve discovered one additional problem that could easily confuse some people: the side effects experienced if you download then re-upload a web-created report. Let me explain…
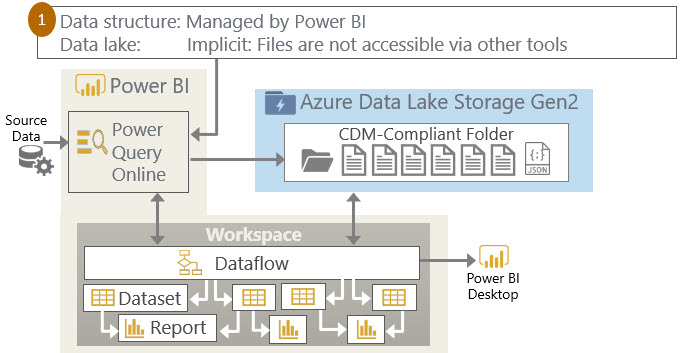
If you create a report directly in the Power BI Service *theoretically* this is like using the Power BI Dataset Live Connection, right? Because we are prompted to choose a dataset, this means we are reusing an existing dataset for our new report. Conceptually this is a great thing, but in reality the hub-and-spoke model (with the dataset being the hub and the various reports being the spokes) only works well if you generate all reports from Power BI Desktop.
Here’s the issue: when you download a web-created report (i.e., created in the Power BI Service), the dataset actually comes with it in the downloaded PBIX file. Unfortunately it does not download as the equivalent of a Power BI Dataset Live Connection. Then, if you turn around and re-upload the PBIX to the Power BI Service --- you end up with a duplicate report and (even worse) a duplicate dataset. I understand the product team wants everything to work seamlessly for busy users — however, I'd much prefer if it behaved seamlessly with a Power BI Dataset Live Connection for the downloaded file.
The moral of this story: Always create all content in Power BI Desktop if you possibly can. Don’t rely on the ability to download from the Power BI Service. I elaborate on this at the bottom of this post. But first, let me walk you through the process.
The Long Version of the Story
I have a dataset published to the Power BI Service which is called Sales Data Model:

I’m going to create a report directly in the web so that we can illustrate the issue I’m concerned about:

I’ll select the existing dataset for my report being created in the web:

Next I’ll create my really fancy report and save it in the Power BI Service:

Other than the name I chose to use, of course we cannot tell from the report list if it was created in the web or from Power BI Desktop. (And to be fair, if we stopped here we wouldn’t actually have any issues with it being used in the Power BI Service.) At this point, I see my report displayed in the report list:
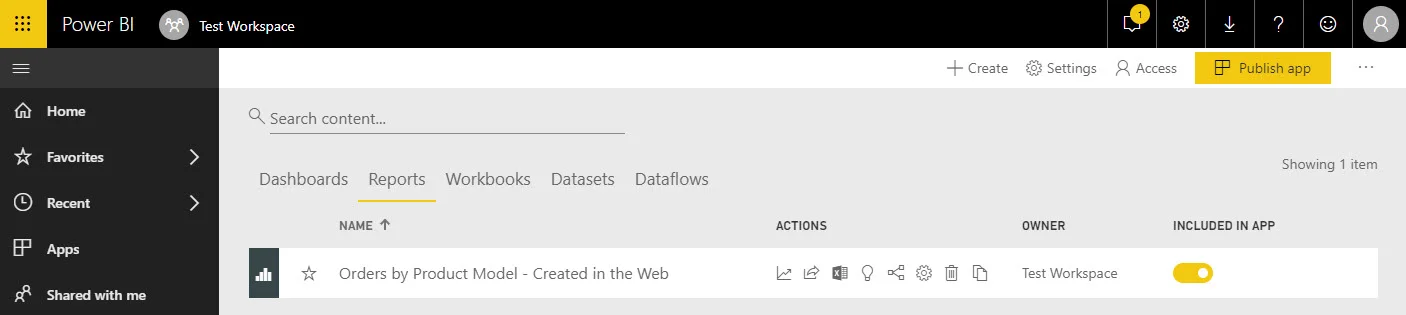
Now let’s download the report we just generated:
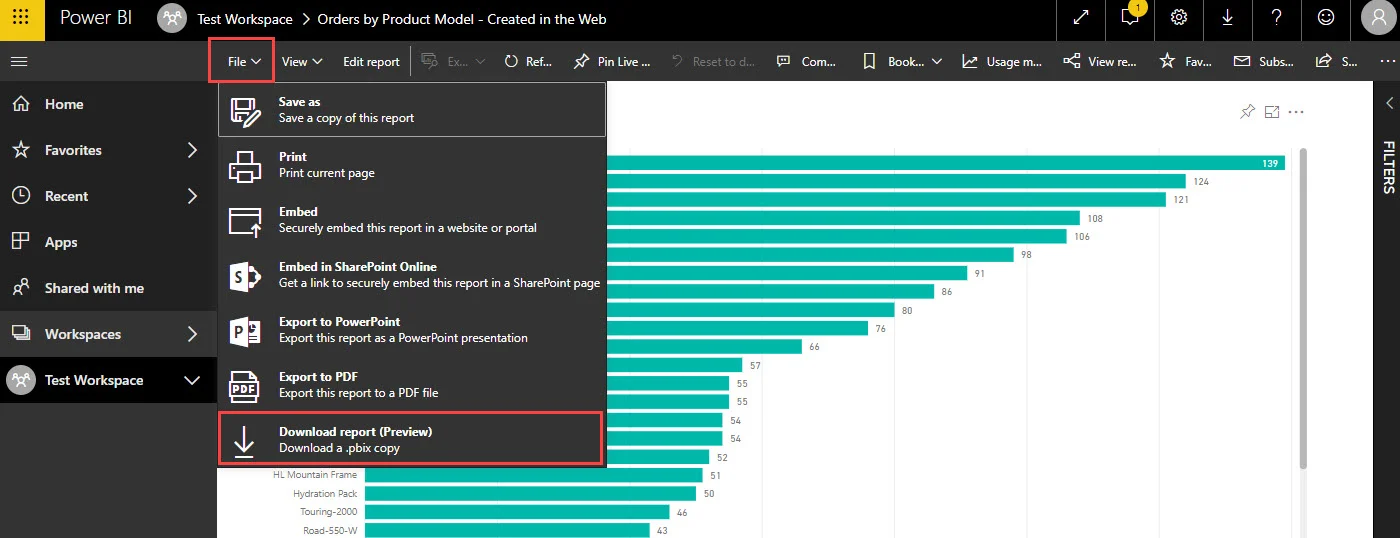
After choosing a location to save the download locally, we get our first clue that something is wrong:
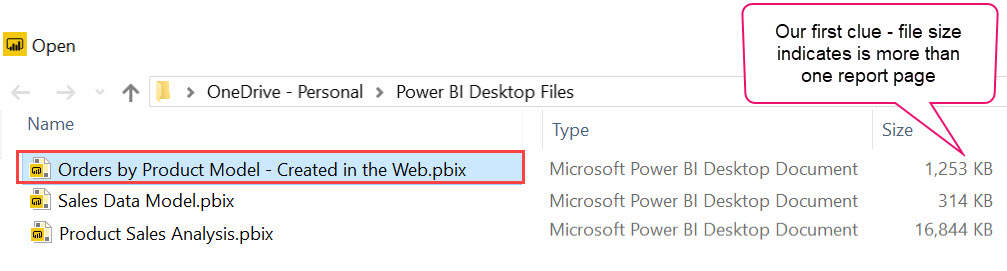
In the above image, see how it’s 1.2 MB? That’s pretty big for my fancy report that has one whole chart. This is our first hint that the dataset has just come along during the download process.
Let’s pretend that we made some edits in Power BI Desktop and that we want to publish them back to the Power BI Service. We can publish the pbix from Desktop, or upload from the Service:

Now that we’ve re-uploaded the edited pbix file, we see the issues. The first issue is we now have two reports named the same thing:
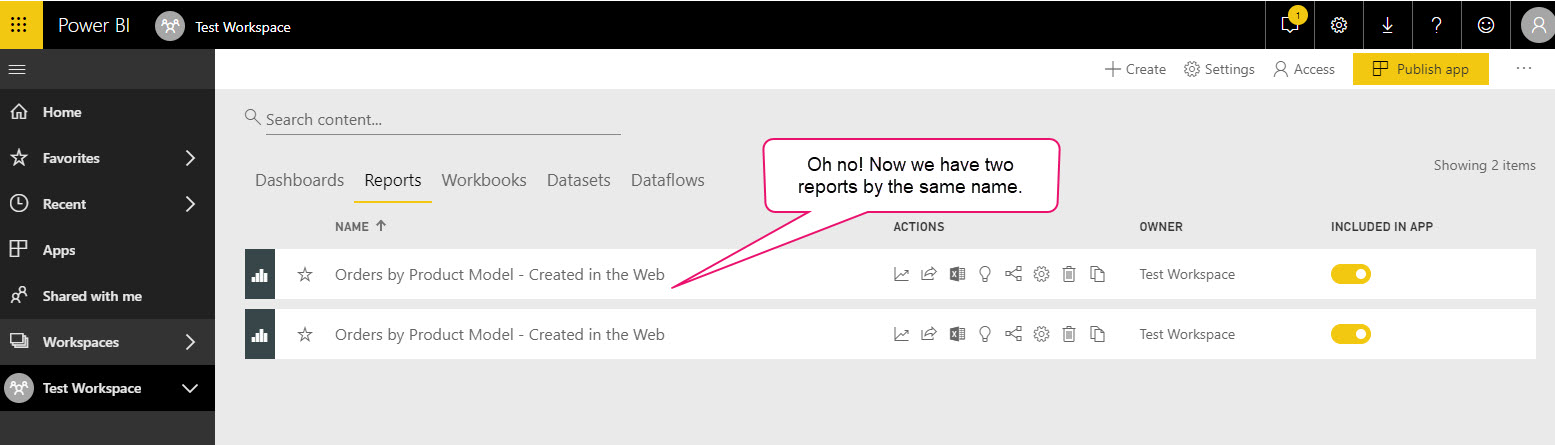
And the second issue, even worse, is we have duplicate datasets (this occurred since the dataset came along during the download):

Summary of Recommendations
Make it a standard practice to always create reports in Power BI Desktop rather than the Power BI Service. This has the following advantages:
You always know that the Power BI Desktop file saved to your standard location is the latest version because you trust your process.
You always have version history available (assuming that you’re using a standard location such as OneDrive for Business, SharePoint Online, or similar).
You have explicit control over what the dataset is doing: import, live connection, or DirectQuery. Use a Power BI Dataset Live Connection whenever you have an existing dataset already published to the Power BI Service that has the data you need (to reduce the # of times the data is stored, reduce work across different datasets, and reduce the # of refresh operations). By doing this from Power BI Desktop, we accomplish exactly what we want in that regard.
If you do want to create reports in the web (or someone with workspace permissions edited a report in the web):
Don’t plan to re-upload the downloaded PBIX file. I heard someone presenting a webinar recently recommended using the web for creating reports & that you always have the downloaded PBIX to fall back on. That makes me nervous because busy business users won’t all understand what is happening and could easily end up with duplicated reports & datasets if they go back and forth as described above.
If you do need to sync up a report in Power BI Desktop, copy and paste the edited visuals from the downloaded PBIX to the actual PBIX. Be sure to discard the downloaded pbix file since it contains the duplicated dataset. This will help you recoup the work that someone did in the web, but not run the risk of duplicating reports and datasets as described above.
Please Vote to Change the Functionality
If you agree with me on this one, please vote for this idea here on the Power BI Ideas site.
You Might Also Like…
Three Ways to Use Power BI Dataflows