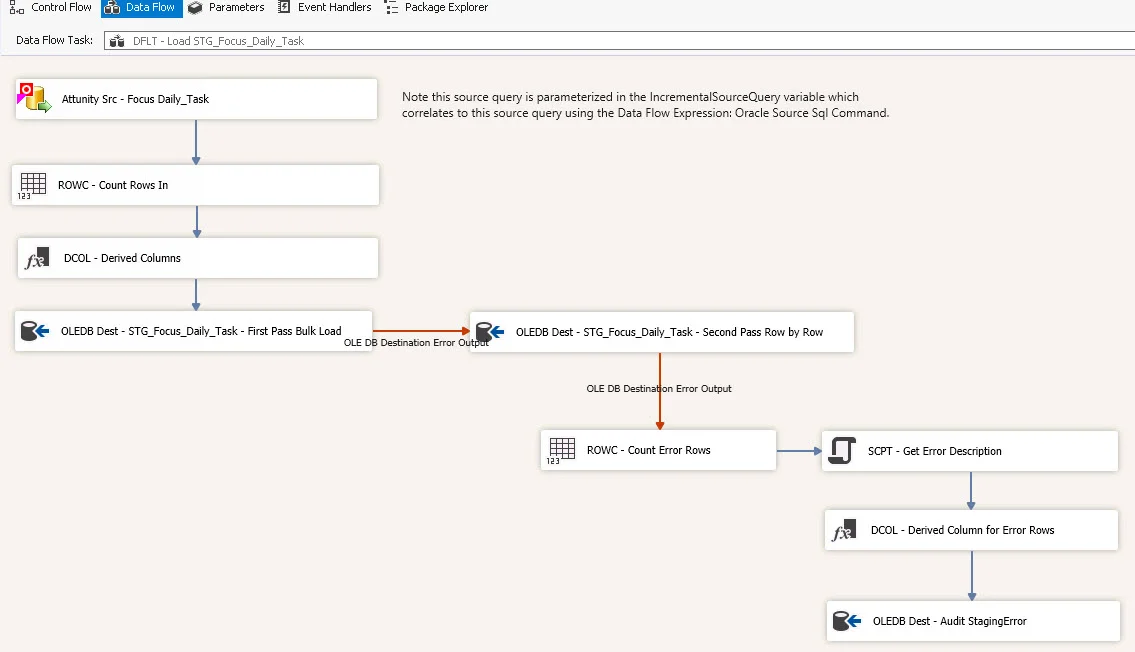
The steps we are going to follow include the following:
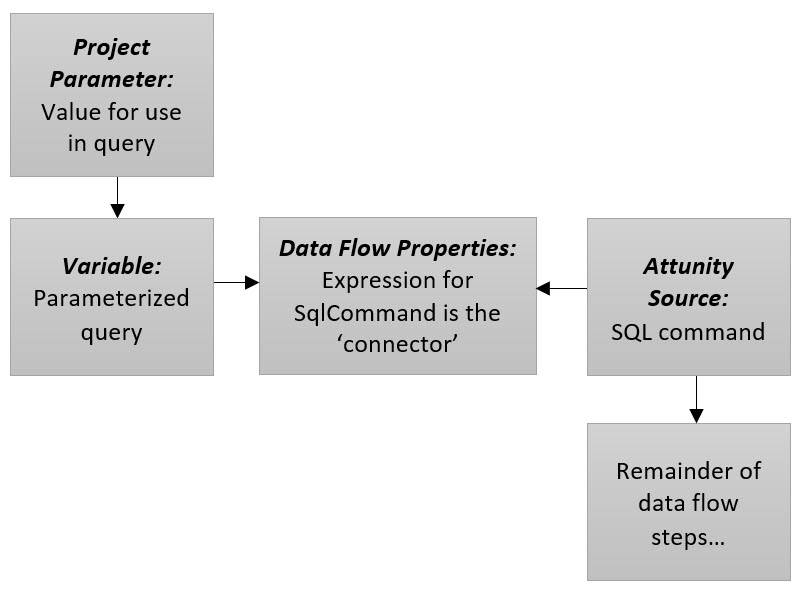
The Attunity connector for Oracle used inside of the SSIS data flow looks a little different than the typical OLE DB connector we most commonly use. Specifically, the Attunity source has two options: “Table Name” and “SQL command.” What the Attunity Oracle Source doesn’t have in this dialog box is “SQL command from variable” (like we see for an OLE DB source).
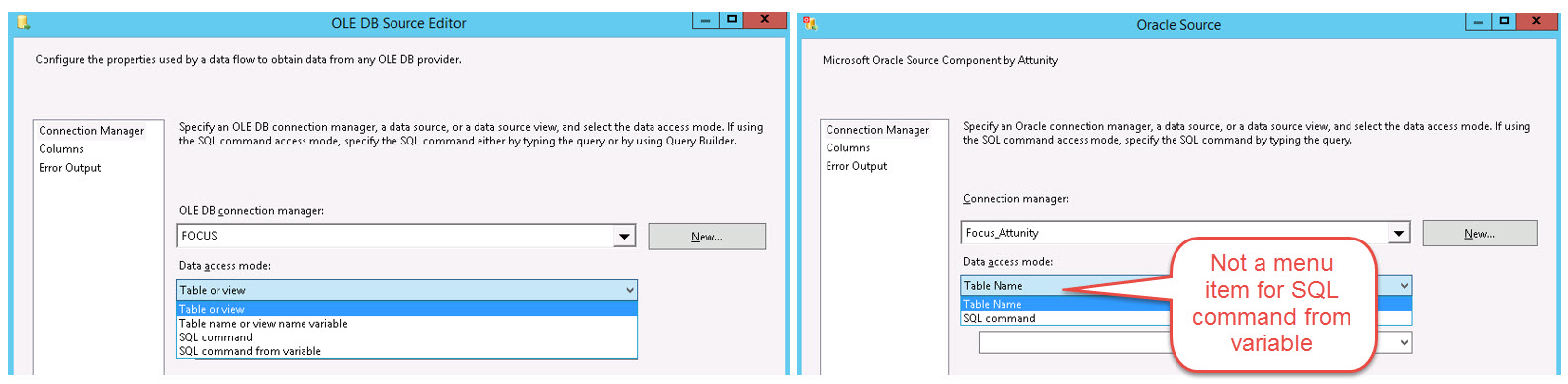
In SSIS, in order to utilize a parameterized query in the data flow source, we typically use a variable that contains the SQL statement and the parameter reference(s). Just because the Attunity Oracle Source dialog box doesn’t show “SQL command from variable” doesn’t mean we can’t get the job done though. It’s just a slightly different process.
Prerequisites: The Attunity connector is already set up in your SSDT environment.
This process references using SQL Server 2012+ and the SSIS project deployment mode.
Step 1. Create a Project Parameter
Since the source query will be parameterized, first we need a place to store this parameter value. The best choice if the value is to be shared across packages is a project-level parameter. You could also use a package-level parameter if it’s not going to be shared across more than one package, and still get the benefit of being able to change the value at runtime if necessary (editing the value at runtime is why we like using a parameter better than a variable for the value of the parameter).
In this example the project parameter is called IncrementalDays_TaskDate which, in our case, means we are going to bring in a 3-day window of time.

Step 2. Create a Variable for the Parameterized Source Query
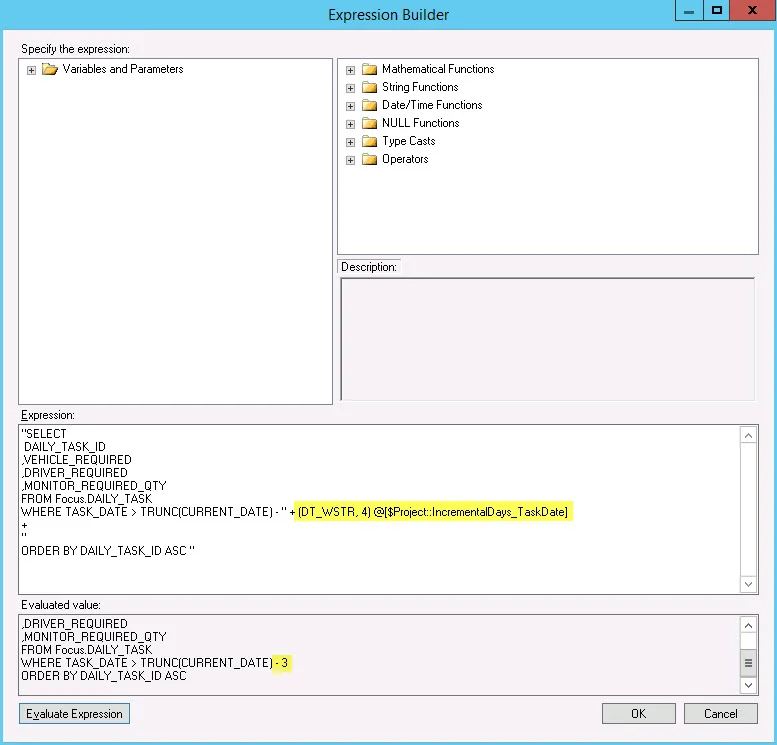
Here’s a simple query example where I’ve pulled in the project parameter created in step 1. This is inside of the expression builder of a variable. Note that in the expression builder, the text is surrounded by double quotes ( " ) and plus signs ( + ) concatenate the text with the parameterized portion. By clicking the "Evaluate Expression" button, we see the 3 day value as per the value in our project parameter.
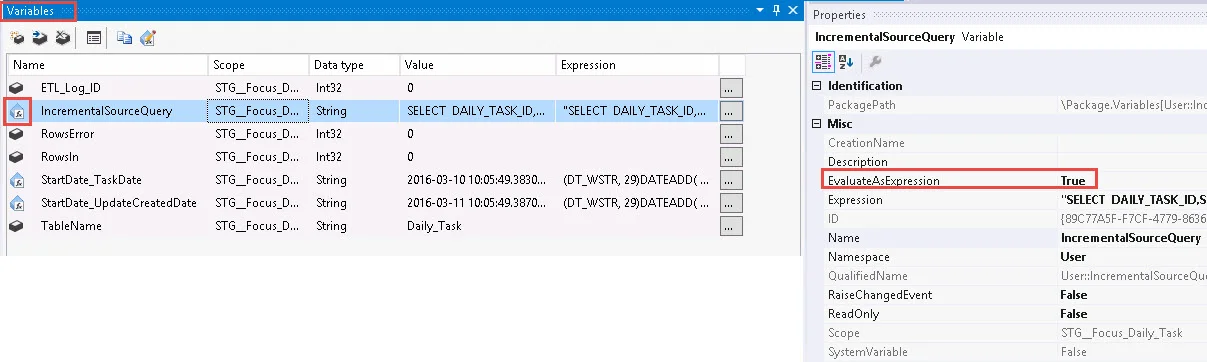
Also, double check the EvaluateAsExpression is set to True in the properties of your variable.
Step 3. Add Attunity Source to Data Flow
Add the Oracle Source to the data flow. Next we want to change its data access mode to “SQL command” and add a temporary query (with the same columns as the real query) to get the metadata passed to the SSIS package. Based on the where clause I used, I know that no rows will return but that’s ok -- the purpose here is (a) to make sure Table is *not* selected anymore, and (b) to get the column metadata picked up by SSIS.
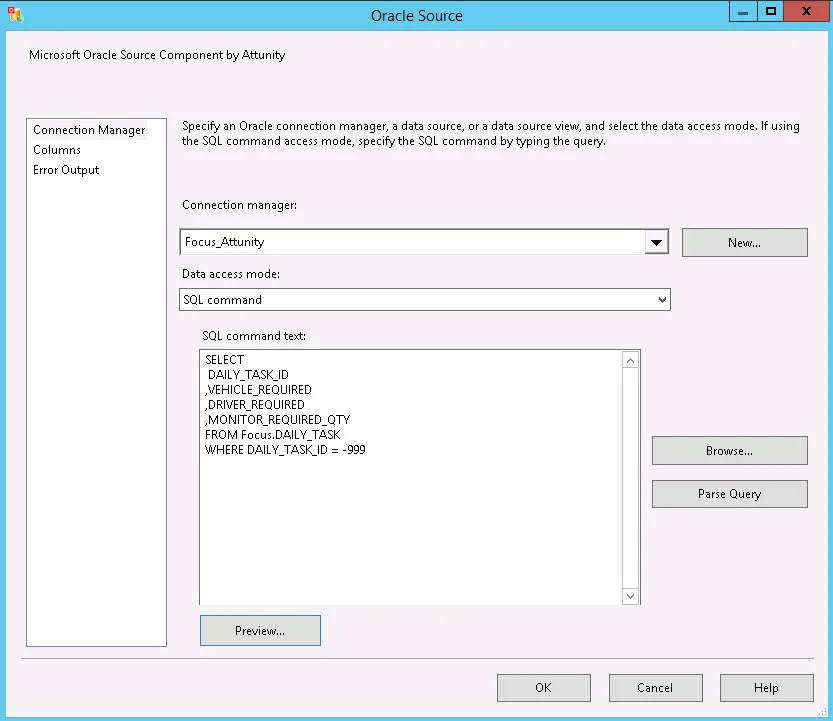
This might seem like somewhat a silly step since it includes a temporary query we won’t keep, but things really worked out more smoothly for me when I didn’t try to skip around it.
Now we have the pieces in place & we just need to connect up our parameterized query in the variable to the Attunity source so that temporary query gets overwritten by the real one.
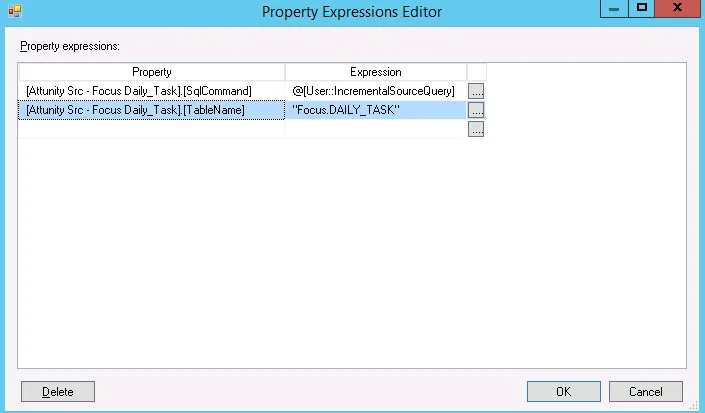
Step 4. Set Data Flow Expressions
Click anywhere on the Data Flow canvas (i.e., so the context is not on any single object). The Properties pane should contextually show the Data Flow properties.
Locate the Expressions section in the properties pane. Click the ellipses next to Expressions.

In the Property Expressions Editor, click the drop-down in the Property. Locate the SqlCommand property for your Attunity source (the first part of the name will differ based on what you named it). Set the expression to be your variable. Be careful not to re-type the SQL statement here or anything – we really just want this expression to be a connector between the SQL command in the Attunity source and the variable that’s parameterized.
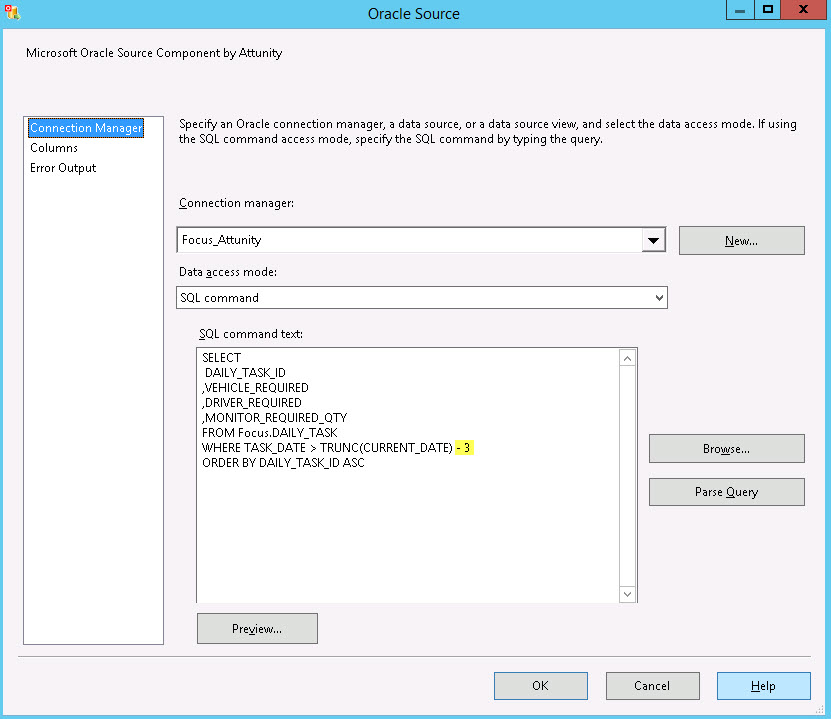
Step 5. Verify SQL Query Changed in the Attunity Source
Now go back to the Attunity Oracle Source and edit it. Your ‘fake’ SQL query from Step 3 should be replaced with the results of the parameterized one. In the screen shot below how we see the 3-day window of time we originally set in the project parameter. You can click Preview if you like as well, to check the query parses and returns a resultset properly.
At this point, I recommend putting an annotation next to the Attunity source as a reminder that this is parameterized. It’s a little too easy to forget and just edit the source query directly in the SQL window – which will just be overwritten by the expression thus potentially causing a bit of frustration later.
So that’s it. Now you can continue on and finish the package as you normally would.