Back in 2013 I announced I'd be joining BlueGranite's team. Well, it's like Groundhog Day because I'm joining BlueGranite again. Let me explain...
For 3 years I worked as a solution architect for BlueGranite, a data-oriented consulting firm focused on BI & analytics. In the fall of 2016 I made a change to an in-house BI role at SentryOne. And although this past year has been great in many ways, I missed some things about my prior role, company, and coworkers. So, I'm headed back to BlueGranite. I'm looking forward to working on interesting customer projects with the wicked-smart people at BlueGranite. Consulting is a good fit for me because it pushes me to stay current on technology & industry changes, and I really need to be learning something new all the time to be happy work-wise.
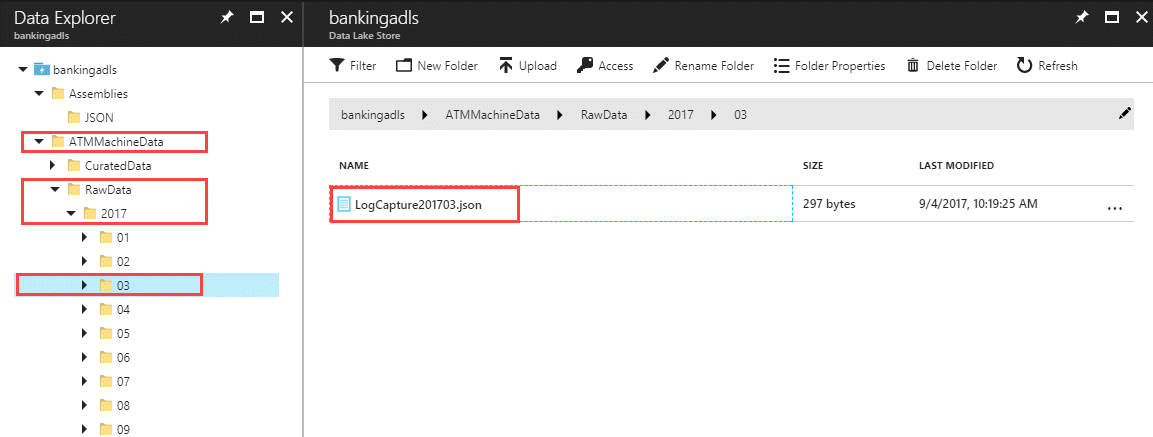
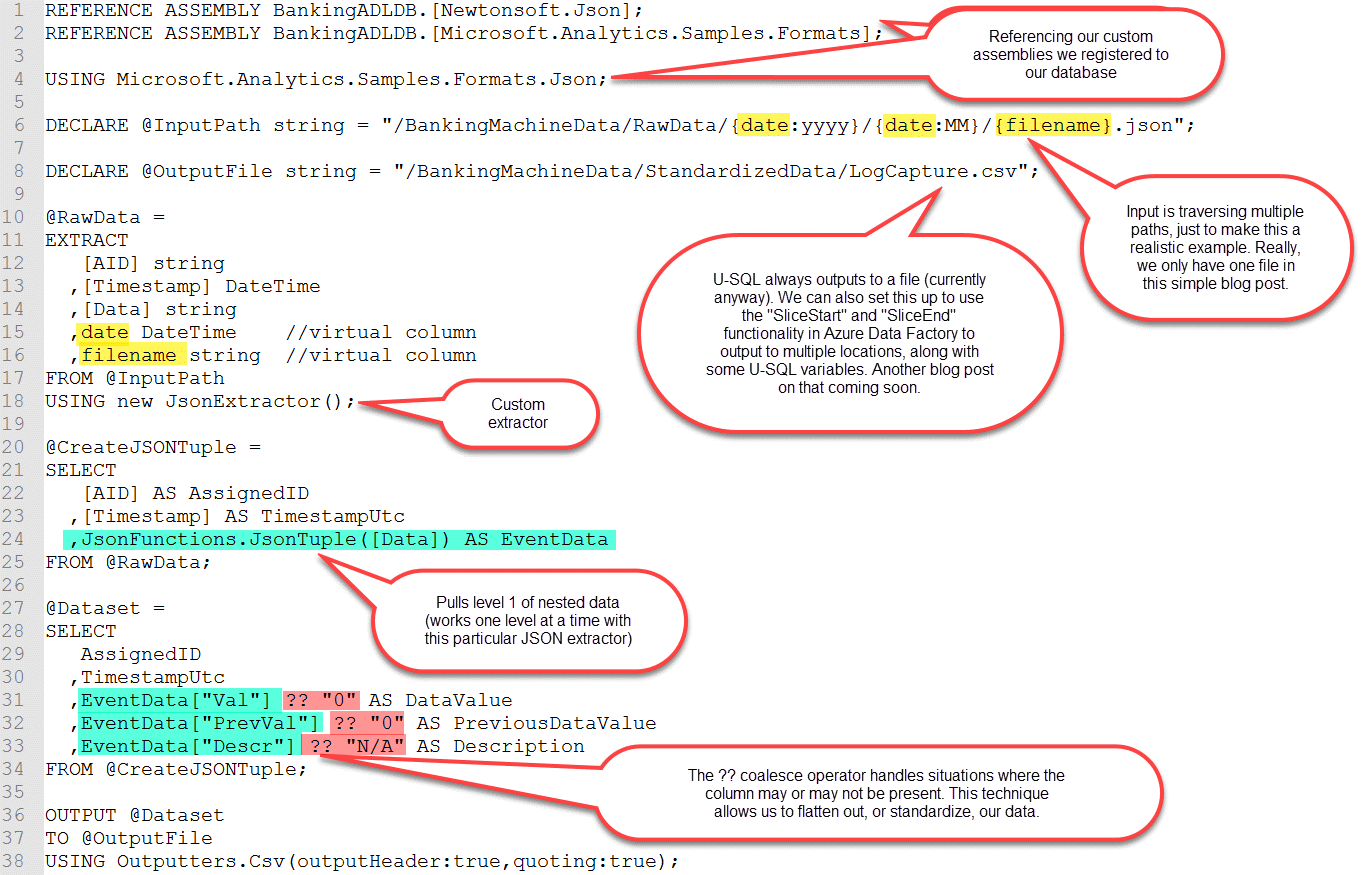
SentryOne is an awesome place - these people care deeply about doing good work. I'm happy I spent a year there. Even though it didn't end up being a perfect fit, it helped me identify what I value most career-wise. And, I still get to accompany the SentryOne team at PASS Summit (how cool is that?!?) to deliver a session at their bootcamp on Tuesday, Oct. 31st. During the bootcamp I'll discuss my telemetry project which involved numerous Azure services.

Aspects of the data lake portion of that implementation will be discussed at my pre-conference workshop at SQL Saturday Charlotte coming up on Oct. 13th. (Tickets are still available. Shameless plug, I know, I know.) If you're near Charlotte and haven't registered for the SQL Saturday training event on Oct. 14th, you can find more info here: http://www.sqlsaturday.com/683/eventhome.aspx. I'm also delivering the workshop at SQL Saturday Washington DC on Dec. 8th.
My husband says this is a little like a woman who remarries her ex-husband. (Yeah, he's a little out there sometimes, heh heh.) I'm not sure that's quite the right analogy, but I certainly am excited to rejoin the BlueGranite team.