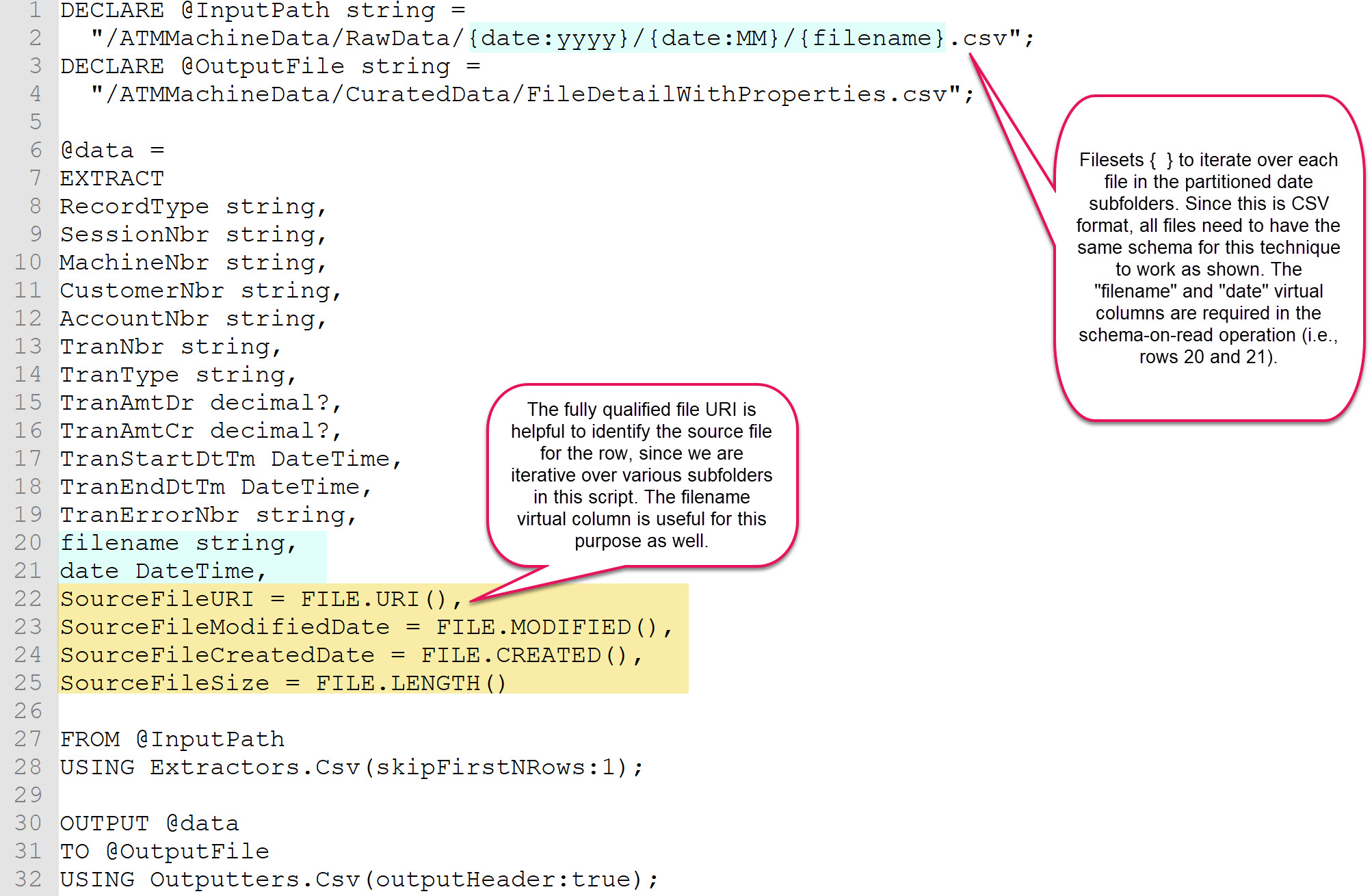
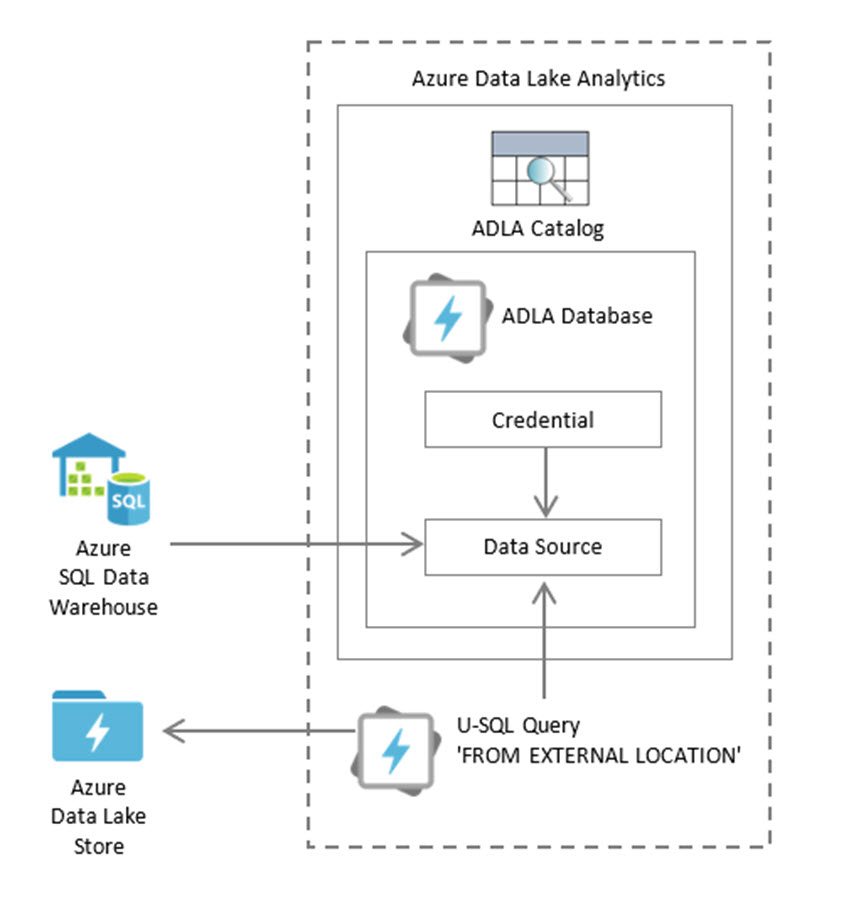
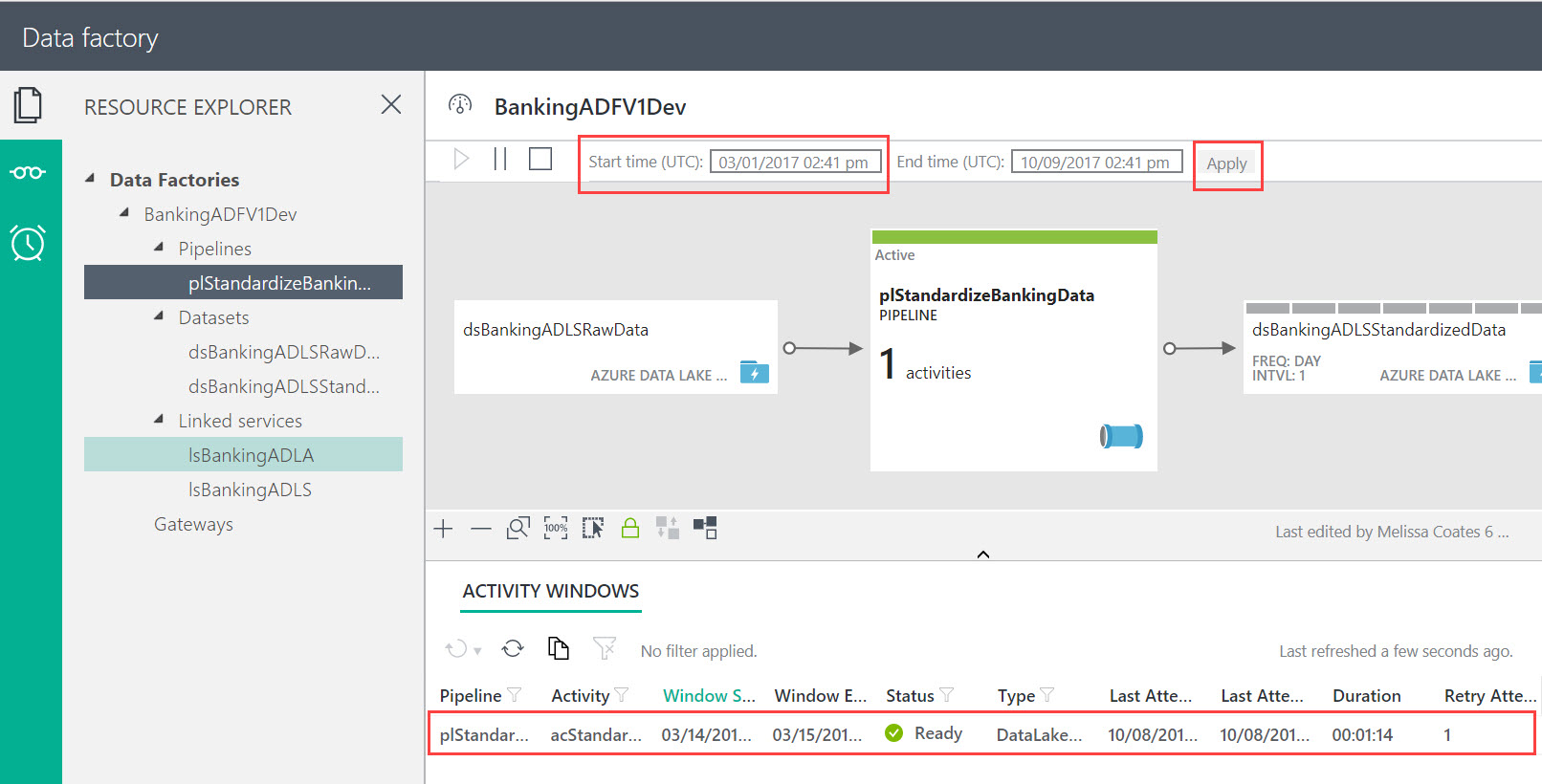
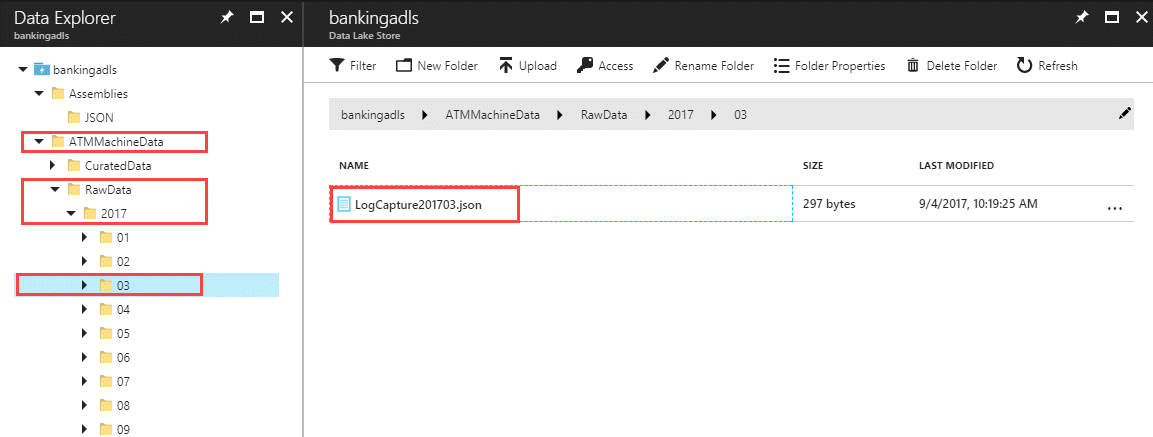
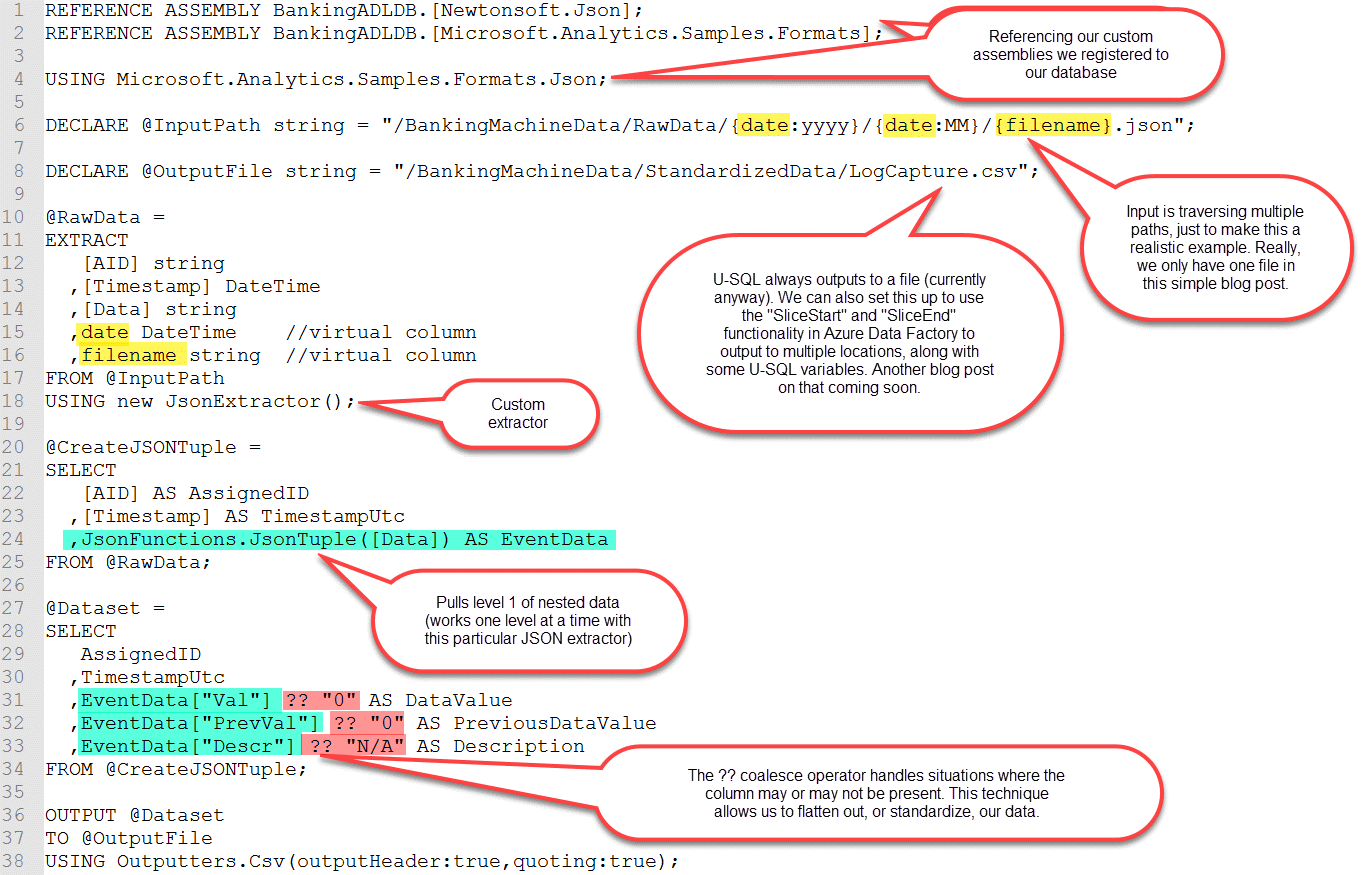
Step 6: Create Azure Data Factory Components
The following ADF scripts include two linked services, two datasets, and one pipeline.
In both linked services you will need to replace several things (as well as the account name and resource group name). Also, be sure NOT to hit the authorize button if you're creating the linked services directly in the portal interface (it's actually a much better idea to use Visual Studio because all of these files can be source-controlled and you can use configuration files to direct deployments to Dev, Test, and Prod which have different values for IDs, keys, etc). You may also want to change the linked services names - mine is called lsBankingADLA (or S) to coincide with what my actual services are called -- but without the Dev, Test, Prod suffix that they have for real (because we need to propagate the linked services without changing the names).
Linked Service for Azure Data Lake Analytics
{
"name": "lsBankingADLA",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<YourADLAName>",
"dataLakeAnalyticsUri": "azuredatalakeanalytics.net",
"servicePrincipalId": "<YourApplicationIDForTheServicePrincipal>",
"servicePrincipalKey": "<YourComplicatedPWForAppRegistration>",
"tenant": "<YourAADDirectoryID>",
"subscriptionId": "<YourSubscriptionID>",
"resourceGroupName": "<YourResourceGroupWhereADLAResides>"
}
}
}
Linked Service for Azure Data Lake Store
{
"name": "lsBankingADLS",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "adl://<YourADLSName>.azuredatalakestore.net/",
"servicePrincipalId": "<YourApplicationIDForTheServicePrincipal>",
"servicePrincipalKey": "<YourComplicatedPWForAppRegistration>",
"tenant": "<YourAADDirectoryID>",
"subscriptionId": "<YourSubscriptionID>",
"resourceGroupName": "<YourResourceGroupWhereADLSResides>"
}
}
}Dataset for the Raw JSON Data
{
"name": "dsBankingADLSRawData",
"properties": {
"published": false,
"type": "AzureDataLakeStore",
"linkedServiceName": "lsBankingADLS",
"typeProperties": {
"fileName": "{year}/{month}/{day}.json",
"folderPath": "ATMMachineData/RawData/",
"format": {
"type": "JsonFormat"
},
"partitionedBy": [
{
"name": "year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
}
]
},
"availability": {
"frequency": "Day",
"interval": 1
},
"external": true,
"policy": {}
}
}
Dataset for the Standardized CSV Data
{
"name": "dsBankingADLSStandardizedData",
"properties": {
"published": false,
"type": "AzureDataLakeStore",
"linkedServiceName": "lsBankingADLS",
"typeProperties": {
"fileName": "SpecifiedInTheUSQLProcedure.csv",
"folderPath": "ATMMachineData/StandardizedData/{year}/{month}",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"nullValue": "N/A",
"firstRowAsHeader": true
},
"partitionedBy": [
{
"name": "year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
}
]
},
"availability": {
"frequency": "Day",
"interval": 1,
"anchorDateTime": "2017-03-14T00:00:00Z"
}
}
}Pipeline with U-SQL Activity to Run the Procedure in ADLA
{
"name": "plStandardizeBankingData",
"properties": {
"description": "Standardize JSON data into CSV, with friendly column names & consistent output for all event types. Creates one output (standardized) file per day.",
"activities": [
{
"type": "DataLakeAnalyticsU-SQL",
"typeProperties": {
"script": "BankingADLDB.dbo.uspCreateStandardizedDataset(System.DateTime.Parse(@DateSliceStart), System.DateTime.Parse(@DateSliceEnd));",
"degreeOfParallelism": 30,
"priority": 100,
"parameters": {
"DateSliceStart": "$$Text.Format('{0:yyyy-MM-ddTHH:mm:ssZ}', SliceStart)",
"DateSliceEnd": "$$Text.Format('{0:yyyy-MM-ddTHH:mm:ssZ}', SliceEnd)"
}
},
"inputs": [
{
"name": "dsBankingADLSRawData"
}
],
"outputs": [
{
"name": "dsBankingADLSStandardizedData"
}
],
"policy": {
"timeout": "06:00:00",
"concurrency": 10,
"executionPriorityOrder": "NewestFirst"
},
"scheduler": {
"frequency": "Day",
"interval": 1,
"anchorDateTime": "2017-03-14T00:00:00Z"
},
"name": "acStandardizeBankingData",
"linkedServiceName": "lsBankingADLA"
}
],
"start": "2017-03-14T00:00:00Z",
"end": "2017-03-15T00:00:00Z",
"isPaused": false,
"pipelineMode": "Scheduled"
}
}
A few comments about the pipeline: