
Updated as of 6/10/2018
I've spent a lot of time this past year learning about and thinking about data lakes. Mostly I've been interested in how to integrate a data lake alongside existing investments without making a mess of things.
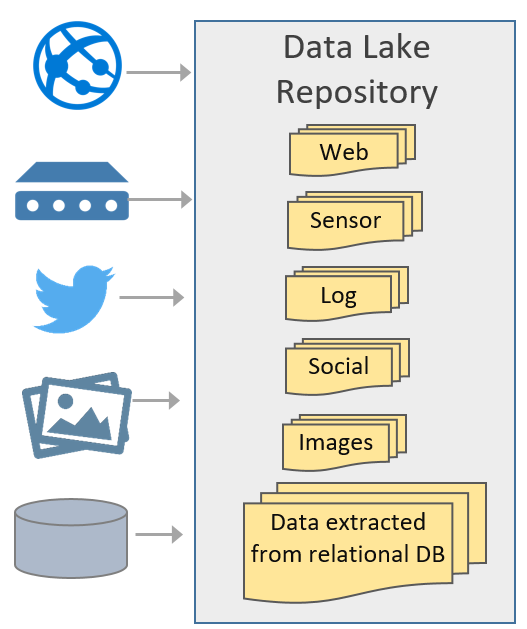
A data lake is one piece of an overall data management strategy. Conceptually, a data lake is nothing more than a data repository. The data lake can store any type of data. Cost and effort are reduced because the data is stored in its original native format with no structure (schema) required of it initially.
Data lakes usually align with an "ELT" strategy which means we can Extract and Load into the data lake in its original format, then Transform later *if* a need presents itself. An "ELT" strategy goes along with the "Schema on Read" technique that is prevalent in the big data world. It's become prevalent because you're able to store the data relatively easily with less up-front time investment, then query the data "where it lives" without being required to relocate the data first (though you may want to later after a solution is productionized).
Conversely, traditional data warehousing typically follows at "ETL" strategy in which the Transformation occurs before the Load to the data warehouse - this is referred to a "Schema on Write" because the schema, i.e., structure of the data, must be defined before the data is loaded to the data warehouse. This takes time and effort to do correctly. It also means we typically need to define use cases ahead of time in order to validate the schema is correct. We can also expect the use cases and needs to evolve over time - this is a good thing, but can be challenging to implement sometimes.
The way I see it, the term data lake is mostly conceptual since a data lake can be comprised of HDFS (Hadoop Distributed File System), other various Hadoop projects, NoSQL DBs, in-memory DBs, which can coexist with relational DBs.
Use Cases For a Data Lake
There are a variety of ways you can use a data lake:
- Ingestion of semi-structured and unstructured data sources (aka big data) such as equipment readings, telemetry data, logs, streaming data, and so forth. A data lake is a great solution for storing IoT (Internet of Things) type of data which has traditionally been more difficult to store, and can support near real-time analysis. Optionally, you can also add structured data (i.e., extracted from a relational data source) to a data lake if your objective is a single repository of all data to be available via the lake.
- Experimental analysis of data before its value or purpose has been fully defined. Agility is important for every business these days, so a data lake can play an important role in "proof of value" type of situations because of the "ELT" approach discussed above.
- Advanced analytics support. A data lake is useful for data scientists and analysts to provision and experiment with data.
- Archival and historical data storage. Sometimes data is used infrequently, but does need to be available for analysis. A data lake strategy can be very valuable to support an active archive strategy.
- Support for Lambda architecture which includes a speed layer, batch layer, and serving layer.
- Preparation for data warehousing. Using a data lake as a staging area of a data warehouse is one way to utilize the lake, particularly if you are getting started.
- Augment a data warehouse. A data lake may contain data that isn't easily stored in a data warehouse, or isn't queried frequently. The data lake might be accessed via federated queries which make its separation from the DW transparent to end users via a data virtualization layer.
- Distributed processing capabilities associated with a logical data warehouse.
- Storage of all organizational data to support downstream reporting & analysis activities. Some organizations wish to achieve a single storage repository for all types of data. Frequently, the goal is to store as much data as possible to support any type of analysis that might yield valuable findings.
- Application support. In addition to analysis by people, a data lake can be a data source for a front-end application. The data lake might also act as a publisher for a downstream application (though ingestion of data into the data lake for purposes of analytics remains the most frequently cited use).

Planning a Data Lake
As we discussed above, a data lake reduces the up-front effort of getting data stored because we aren't absolutely required to structure it first. However, that doesn't mean there's no planning at all. There's various things you want to consider as you're planning a data lake -- to prevent it from becoming the dreaded data swamp -- including things such as:
- Ingestion needs (push / pull via streaming or batch)
- Security around data access
- Data retention and archival policies
- Encryption requirements
- Governance
- Data quality
- Master data management
- Validity checks necessary
- Metadata management
- Organization of data for optimal data retrieval
- Scheduling and job management
- Logging and auditing
- To what extent data federation will be utilized
- Enrichment, standardization, cleansing, and curation needs
- Technology choices comprising the overall data lake architecture (HDFS, Hadoop components, NoSQL DBs, relational DBs, etc.)
- Modular approach to the overall design
You definitely want to spend some time planning out how the data will be organized so that finding the data is as straightforward as possible. Just like with planning anything where data is stored (for example, a regular file share, or a SharePoint document library, etc.), you usually want to consider subject areas along with user groups and security boundaries.

There's many different ways to organize a data lake. For batch data loads, here's one example:
Raw Data
Organizational Unit
Subject Area
Original Data Source
Object
Date Loaded
File(s)
This structure could translate into something like:
East Division
Sales
Salesforce
CustomerContacts
2016
2016_12
2016_12_01
CustContact_2016_12_01.txt
The nice thing about the organizational unit being at the top is there is a clear security boundary. However, that might lead to siloed data and/or duplicated data.
Key points about the "Raw Data" layer:
- The raw data is usually considered immutable data (i.e., unchangeable). This allows you to go back to a point in time if necessary. It should be the lowest granularity, most atomic, data you are able to obtain.
- It's possible that bad data could be deleted from the raw data layer, but generally deletes rare.
- The speed at which data arrives should be a non-issue for the data lake. Therefore, you want your data lake to be able to accommodate a batch layer (data loaded from batch processes) and a speed layer (data loaded from streaming data or near real-time applications).
- The choice of data format is particularly crucial in the raw data layer since the performance of writes for low-latency data is critical. Although something like CSV is easy to use and human-readable, it doesn't perform well at larger scale. Other formats like Parquet or ORC perform better. To decide on format, think about file sizes, if a self-describing schema is desired (like JSON or XML), data type support, if schema changes over time are expected, performance you need for write and read, and the integration with other systems.
- The raw data layer is often partitioned by date. If there's an insert/update date in the source that can be relied upon, you can organize incremental data loads by that date. If there's not a reliable date to detect changes, then you need to decide if the source is copied over in its entirety every time the data load executes. This correlates to what extent you need to detect history of changes over time--you probably want to be liberal here since all requirements aren't identified upfront.
- When partitioning by date, generally the dates should go at the end of the path rather than the beginning of the path. This makes it much easier to organize and secure content by department, subject area, etc.
- The rule of thumb is to not mix data schemas in a single folder so that all files in a folder can be traversed with the same script. If a script is looping through all the files in a folder--depending on the technique you are using, a script might fail if it finds a different format.
- The raw data should be stored the same as what's contained in the source. This is much like how we would stage data for a data warehouse, without any transformations, data cleansing, or standardization as of yet. The only exception to this would be to add some metadata such as a timestamp, or a source system reference, directly within the data itself (having the timestamp can be very helpful if your system needs to tolerate duplicates, for instance from retry logic).
- Very, very few people have access to the raw data layer. Just like staging for a data warehouse is considered the back-end "kitchen" area, the raw data layer is usually hands-off for most users except for highly skilled analysts or data scientists.
- The above sample raw data structure emphasizes security by organizational unit. The tradeoff here is a data source table may be duplicated if used by different organizational units. Therefore, a different type of structure might make more sense depending on your needs.
- Some architectural designs call for a transient/temporary landing zone prior to the raw data zone. An intermediate zone prior to the raw data zone is appropriate if validity checks need to be performed before the data is allowed to hit the raw data zone. It's also helpful if you need to separate "new data" for a period of time (for instance, to ensure that jobs pulling data from the raw data zone always pull consistent data). Alternatively, some folks refer to a temp/transient zone as the 'speed' layer in a Lambda architecture.
For purposes of permitting data retrieval directly from the data lake, usually a different layer is recommended for the curated data, or specialized data. It could be organized more simply such as:
Curated Data
Purpose
Type
Snapshot Date (if applicable)
File(s)
This structure could translate into something like:
Sales Trending Analysis
Summarized
2016_12_01
SalesTrend_2016_12_01.txt
Key points about the "Curated Data" layer:
- User queries are from the curated data layer (not usually the raw data layer). This area where consumption is allowed is also referred to as a data hub sometimes.
- The curated data layer contains data for specific, known, purposes. This means that the curated data layer is considered "Schema on Write" because its structure is predefined.
- Some data integration and cleansing can, and should occur, in the curated data layer.
- It's not uncommon to restructure data to simplify reporting (ex: standardize, denormalize, or consolidate several related data elements).
- You want to make sure you can always regenerate the curated data on-demand. Regenerating history could be needed for a number of reasons. It helps to recover from an error, should a problem occur. Depending on how schema changes over time are handled, regenerating curated data can help. Perhaps your machine learning algorithms are better now. Or perhaps you've had to delete some customer data from a GDPR request, all the way back to the original raw data.
- To the extent that friendly names can be assigned, rather than cryptic names from a source system, that should be done to improve usability. Anything you can do to make it simpler to use is usually a good time investment in my mind.
- Depending on how far you take it, the curated data layer could be set up similarly to a data warehouse, particularly if you take advantage of some of the Hadoop technologies available to augment the data lake infrastructure.
- You might find that multiple logical data layers to deliver curated data makes sense for your purposes (similar to the concept of different data marts).
It's also very common to include a "sandbox" area in your data lake. This provides your highly trained analysts and data scientists an area where they can run processes and write data output.
Organizing the Data Lake
In the above section are a couple of organization examples. Above all else, the data lake should be organized for optimal data retrieval. Metadata capabilities of your data lake will greatly influence how you handle organization.

Organization of the data lake can be influenced by:
- Subject matter
- Source
- Security boundaries
- Downstream applications & uses
- Data load pattern
- Real-time, streaming
- Incremental
- Full load
- One time
- Time partitioning & probability of data access
- Recent/current data
- Historical data
- Data classification, trust value
- Public information
- Internal use only
- Supplier/partner confidential
- Personally identifiable information (PII)
- Sensitive - financial
- Sensitive - intellectual property
- Business impact
- High (HBI)
- Medium (MBI)
- Low (LBI)
- Data retention policy
- Temporary data
- Permanent data
- Applicable period (ex: project lifetime)
Does a Data Lake Replace a Data Warehouse?
I'm biased here, and a firm believer that modern data warehousing is still very important. Therefore, I believe that a data lake, in an of itself, doesn't entirely replace the need for a data warehouse (or data marts) which contain cleansed data in a user-friendly format. The data warehouse doesn't absolutely have to be in a relational database anymore, but it does need a semantic layer which is easy to work with that most business users can access for the most common reporting needs.
Lessons learned via analysis done from the data lake can often be taken advantage of for the data warehouse (the exact same thing we often say with regard to self-service BI efforts influencing and improving corporate BI initiatives). It is true that agility can be faster when conducting analysis directly from the data lake because you're not constrained to a predefined schema -- anyone who has experienced shortcomings in the data warehouse will appreciate this. For instance, let's say the data warehouse relates the customer and region dimensions to a fact table such as sales. Then someone wants to count customers by region, even if the customer doesn't have any sales. In the DW there's at least a couple of different ways to handle it, but we need to build on the initial schema to handle it (because dimensions usually only relate through facts, not directly to each other). Whereas when you start in the data lake with the question, such as customers by region, you have more freedom and flexibility. However, that freedom and flexibility come at a cost -- data quality, standardization, and so forth are usually not at the same maturity level as the data warehouse. In other words, "schema on read" systems put more burden on the analyst.
There's always tradeoffs between performing analytics on a data lake versus from a cleansed data warehouse: Query performance, data load performance, scalability, reusability, data quality, and so forth. Therefore, I believe that a data lake and a data warehouse are complementary technologies that can offer balance. For a fast analysis by a highly qualified analyst or data scientist, especially exploratory analysis, the data lake is appealing. For delivering cleansed, user-friendly data to a large number of users across the organization, the data warehouse still rules.
Want to Know More?
My next all-day workshop on Architecting a Data Lake is in Raleigh, NC on April 13, 2018.
You Might Also Like...
Zones in a Data Lake
Querying Multi-Structured JSON Files with U-SQL in Azure Data Lake
Why You Should Use an SSDT Database Project For Your Data Warehouse