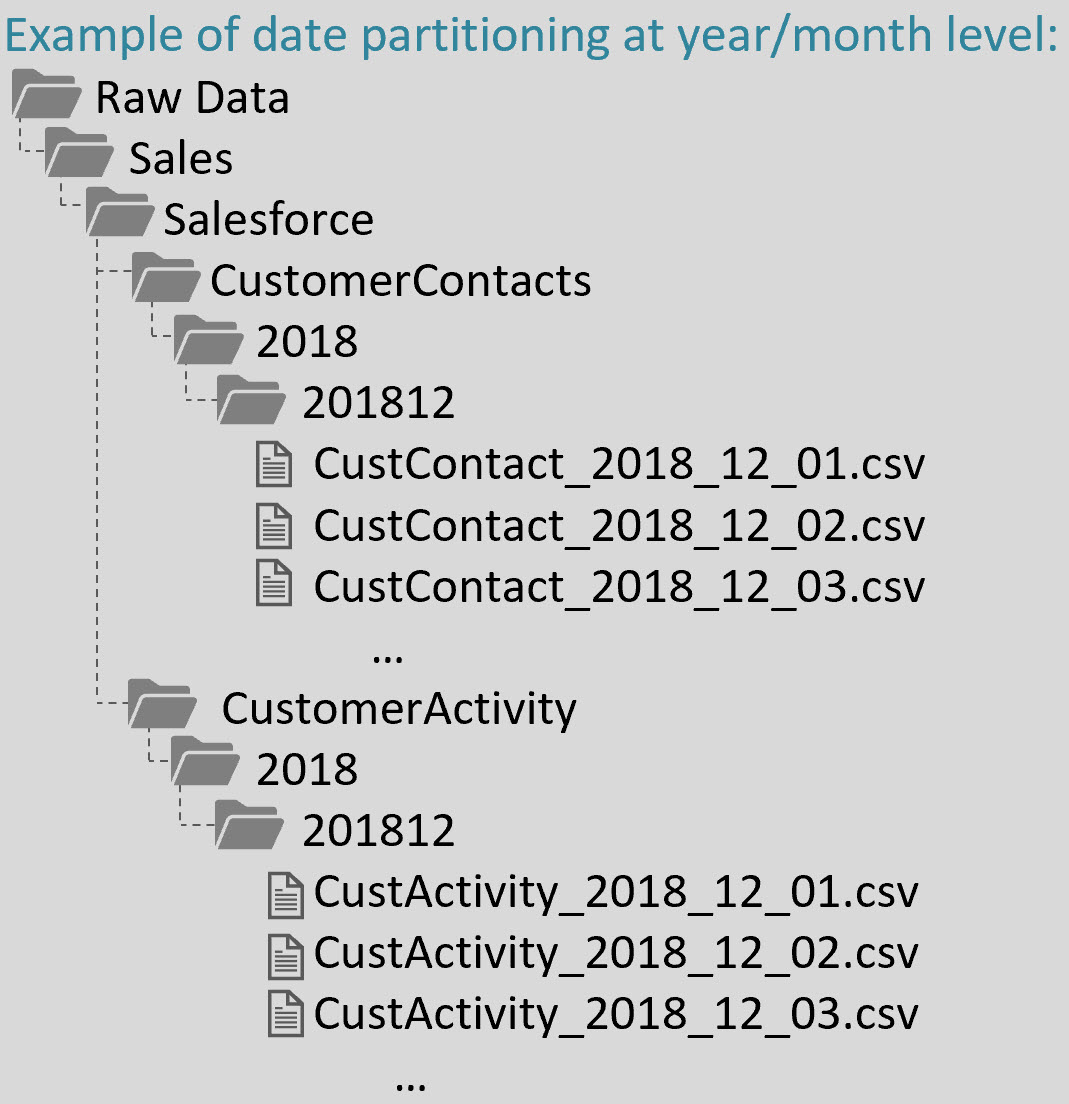
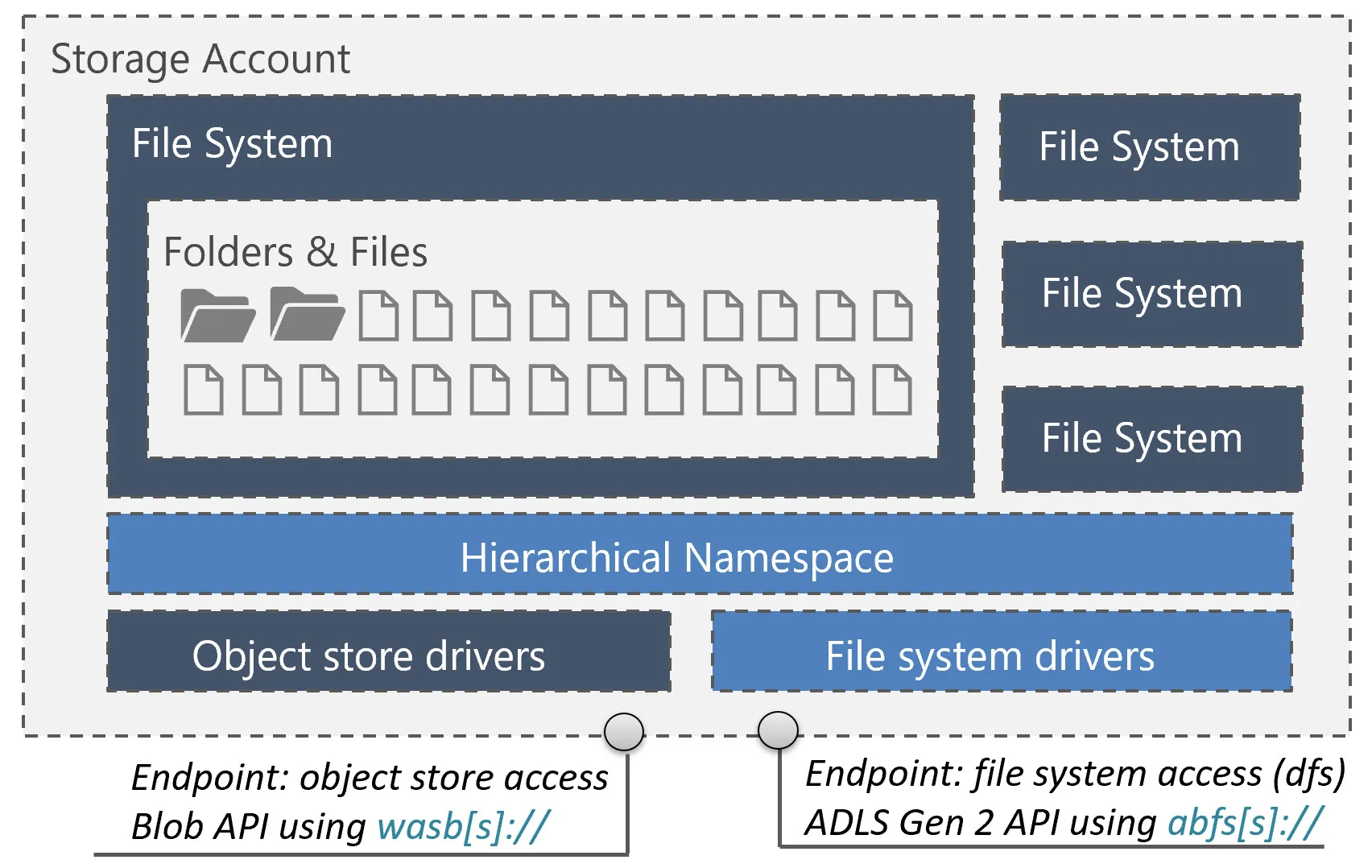
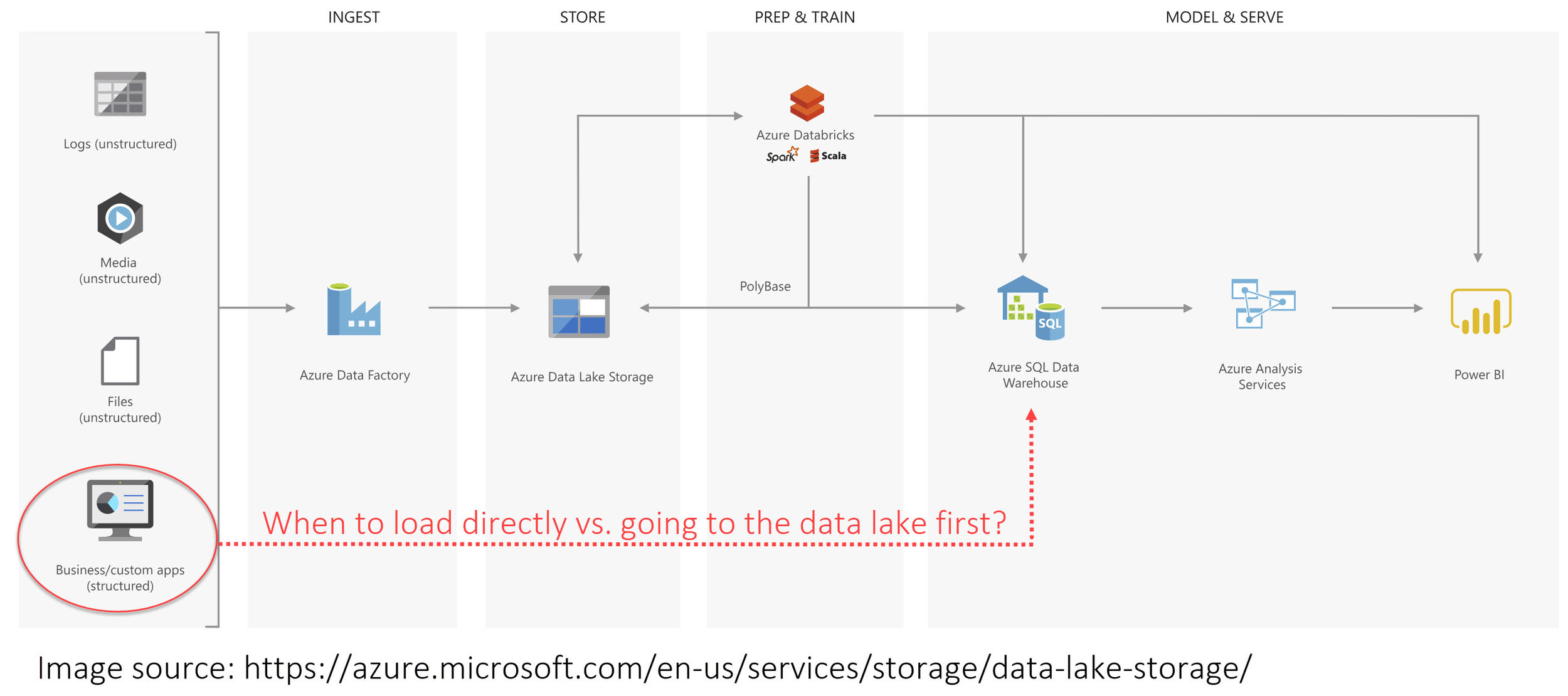
A couple of people have asked me recently about how to 'bone up' on the new data lake service in Azure. The way I see it, there are two aspects: A, the technology itself and B, data lake principles and architectural best practices. Below are some links to resources that you should find helpful.
Learning about ADLS Gen2 Technology
Azure Data Lake Storage Gen2 is new so there is limited info available. However, since it's built upon the foundation of Azure Storage there is quite a lot of information available at the same time (though in all fairness ADLS Gen2 hasn't reached feature parity yet with blob storage). Here are some resources about the technology:

10 Things to Know about Azure Data Lake Storage Gen2
Planning for Accounts, Containers, and file Systems for your Data Lake in Azure Storage
Best Practices for Using Azure Data Lake Storage Gen2
The Azure Blob Filesystem Driver (ABFS): A Dedicated Storage Driver for Hadoop
Azure Data Lake Storage Gen2 Hierarchical Namespace
Use the Azure Data Lake Storage Gen2 URI
Overview of Azure Data Lake Storage Gen2 [video]
Pluralsight Course: Implementing Azure Data Lake Storage Gen2 by Xavier Morera [video—requires subscription]
Learning about Data Lake Principles and Architectural Best Practices
Just like when designing a database, there are some important aspects to designing a data lake that improve usability, security, performance, and governance. This is your enterprise data we're talking about, right? Some up-front planning for how this data is structured is warranted (because yes, a data lake is more agile...but not so agile that it becomes the dreaded swamp). Here are a few resources for learning about principles and best practices:
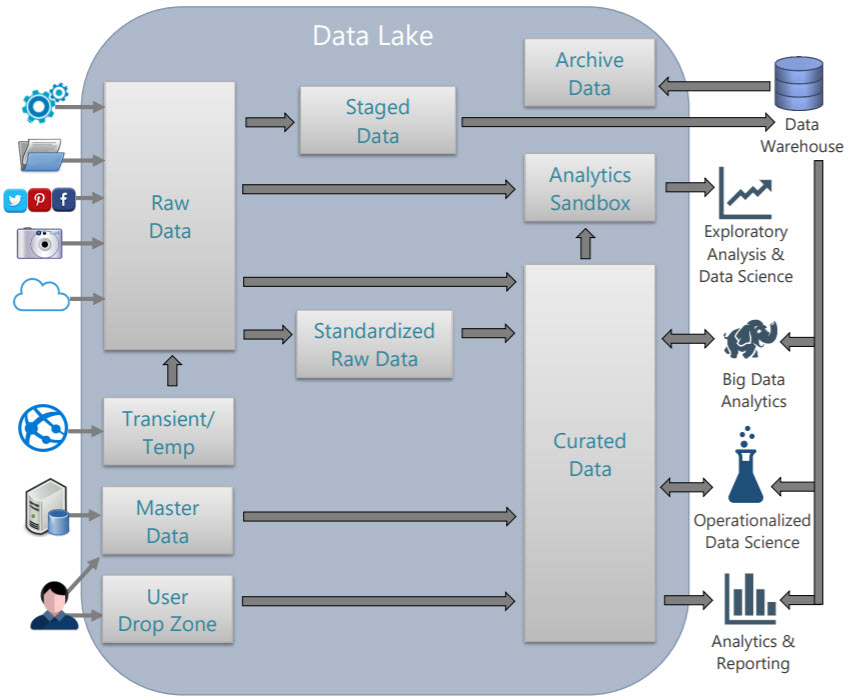
Data Lake Use Cases and Planning Considerations
FAQs About Organizing a Data Lake
When Should We Load Relational Data to a Data Lake?
Data Lakes in a Modern Data Architecture [ebook]
The Data Lake Manifesto: 10 Best Practices
A Smarter Way to Jump Into Data Lakes
Big Data by Nathan Marz [book] <— This book is getting older now, but the conceptual chapters are excellent. Skip the technology chapters & focus on the concepts & it's a worthwhile read.
There are also several books on data lakes. I don’t have a favorite. Just keep in mind that some things are opinions and personal preferences. Though data lakes are maturing, best practices are still emerging. Many articles and book intros overstate the benefits and under-emphasize the challenges, so watch out for that.
Following the Maturity of ADLS Gen2
These are two important URLs for tracking what is and isn't supported in ADLS Gen2:
Upgrade Your Big Data Analytics Solutions from ADLS Gen1 to ADLS Gen2