
Did you know there are two ways to do federated queries with Azure Data Lake Analytics (ADLA)? By federated queries, I mean a query that combines (federates) data from multiple sources -- in this case, from within Azure Data Lake and another data store. Federated queries are one aspect of data virtualization which helps us to access data without requiring the physical movement of data or data integration:

The two methods for federated queries with U-SQL and ADLA are:
- Schema-less (aka "lazy metadata")
- Via a pre-defined schema via an external table
You might be familiar with external tables in SQL Server, Azure SQL Data Warehouse, or APS. In those platforms, external tables work with PolyBase for purposes of querying data where it lives elsewhere, often for the purpose of loading it into the relational database. That same premise exists in Azure Data Lake Analytics as well. However, in the data lake there's two approaches - an external table is still a good idea most of the time but it isn't absolutely required.
Option 1: Schema-Less
Following are the components of making schema-less federated queries work in ADLA:
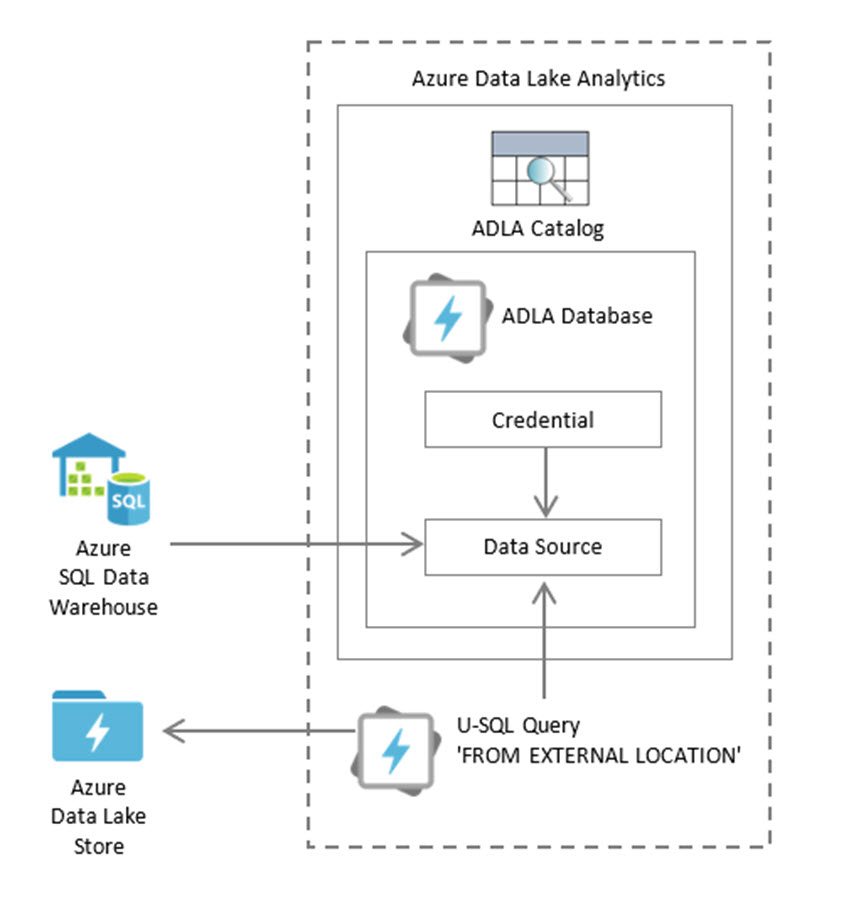
Pros of the schema-less option:
- Access the data quickly for exploration without requiring an external table to be defined in the ADLA Catalog
- More closely aligned to a schema-on-read paradigm because of its flexibility
- Query flexibility: can retrieve a subset of columns without having to define all the columns
Cons of the schema-less option:
- Additional "burden" on the data analyst doing the ad hoc querying with U-SQL to always perform the schema-on-read within the query
- Repeating the same schema-on-read syntax in numerous U-SQL queries, rather than reusing the definition via an external table -- so if the source system table or view changes, it could involve altering numerous U-SQL scripts.
- Requires a rowset in the U-SQL schema-on-read queries - i.e., cannot do a direct join so this approach involves slightly longer, more complex syntax
Option 2: With a Pre-Defined Schema in an External Table
The following introduces an external table to the picture in order to enforce a schema:

Pros of using an external table:
- Most efficient on the data analyst doing the ad hoc querying with U-SQL
- Easier, shorter syntax on the query side because columns and data types have already been predefined in the ADLA Catalog, so a direct join to an external table can be used in the query without having to define a rowset
- Only one external table to change if a modification does occur to the underlying SQL table
Cons of using an external table:
- Schema must remain consistent - a downstream U-SQL query will error if a new column is added to the remote source and the external table has not been kept in sync
- All remote columns must be defined in the external table (not necessarily a big con - but definitely important to know)
In summary, the schema-less approach is most appropriate for initial data exploration because of the freedom and flexibility. An external table is better suited for ongoing, routine queries in which the SQL side is stable and unchanging. Solutions which have been operationalized and promoted to production will typically warrant an external table.
Want to Know More?
During my all-day workshop, we set up each piece step by step including the the service principal, credential, data source, external table, and so forth so you can see the whole thing in action. The next workshop is in Raleigh, NC on April 13, 2018.
You Might Also Like...
Querying Multi-Structured JSON Files with U-SQL
Running U-SQL on a Schedule with Azure Data Factory to Populate Azure Data Lake