How the queries passed from SSAS to the DB engine is very interesting. First, however, let's review the basics of DirectQuery mode in SQL Server Analysis Services (SSAS). All information is as of RC1 (release candidate 1) for SQL Server 2016.
Two Modes for SSAS Tabular Models
When developing an SSAS Tabular model, you can choose one of two options for handling the underlying data:
In-Memory Mode (aka Imported Mode). Stores the data in the in-memory model, so all queries are satisfied by the data imported into the Tabular model's storage engine. This requires the model to be processed for updated data to become available for reporting. This mode is conceptually analogous to MOLAP in SSAS multidimensional models (though the SSAS architecture differs significantly).
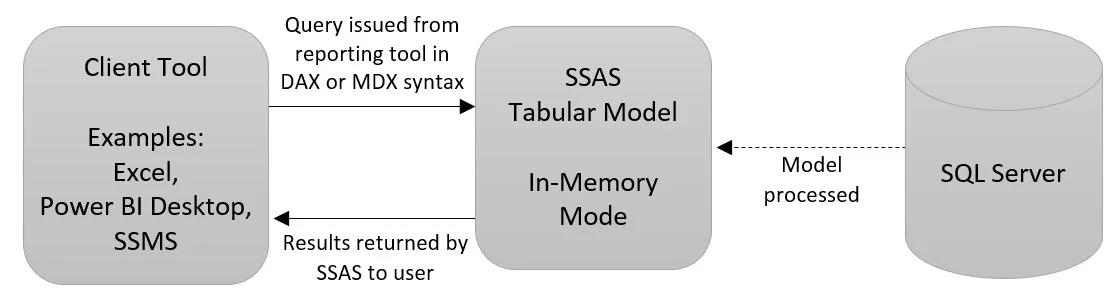
DirectQuery Mode. Leaves the data in the source and sends the queries to the underlying database. In this case there's no processing and SSAS serves as a semantic model to improve the user experience. This mode is conceptually analogous to ROLAP in SSAS multidimensional models (though there are architectural / implementation differences between DirectQuery and ROLAP).

Note that the entire SSAS Tabular model is specified as one of the two modes.
Use Cases for SSAS Tabular in DirectQuery Mode
Most SSAS Tabular models do run in In-Memory mode. However, there are some specific situations where DirectQuery is a viable option.
Near Real-Time Reporting. Low latency for data availability is the primary use case for DirectQuery. Because there's no processing time associated with populating data in SSAS, there's less delay in making data available. SSAS only compiles and deploys metadata. In this situation, you'll want to plan for how to handle contention of read and write activity.
Large Datasets Which Exceed Memory Available. Another situation to consider DirectQuery is if your server doesn't have enough memory to store all of the data. The rule of thumb for storing data in a Tabular in-memory model is to have 2.5x memory, so if your in-memory model size is 50GB, you would require about 125GB of RAM on the server. Therefore, for large datasets that are difficult to fit in memory, DirectQuery can be appealing. In the absence of model processing, SSAS would have much less CPU and memory demands when running in DirectQuery mode (and conversely, the underlying DB engine needs to be beefier).
Relational Database Highly Tuned for Ad Hoc Queries. If you've invested time creating clustered columnstore indexes, partitions, or other query tuning efforts in the underlying database engine, you may be inclined to utilize the source database for live query activity. In that case, the value of SSAS is the semantic layer (i.e., if you have users connecting to the data source and developing their own reports, it is significantly easier for users to navigate an SSAS model where everything is organized and no joins are required).
Most or All Logic Comes from Underlying Database. Only the most straightforward DAX calculations will be able to convert to SQL. If you tend to pass most everything you need into SSAS from the source database, and your SSAS calculations are simple, you should be able to consider DirectQuery mode.
Updates to SSAS Tabular in DirectQuery Mode in SQL Server 2016
Improvements to DirectQuery in SQL Server 2016:
- Performance improvements related the queries that are generated. Queries are less verbose now.
- Additional relational data sources are now supported. Now the options include including SQL Server, APS (PDW), Oracle, and Teradata.
- Support for Row-Level Security in the underlying data source, which is a new feature in SQL Server 2016.
- Calculated columns in the Tabular model are now permitted when in DirectQuery mode. The computation will be pushed down to the database server.
- Excel is now available as a tool to use with DirectQuery mode. Prior to SQL Server 2016, Excel couldn't be used since Excel passes MDX rather than DAX. Note that there's still some limitations which are listed here: https://msdn.microsoft.com/en-us/library/hh230898.aspx.
- Conversion for some of the time intelligence calculations are now supported.
Other Changes to DirectQuery in SQL Server 2016:
- Deployed mode (as seen in SSMS rather than SSDT) is now a more 'pure' DirectQuery mode. The options for 'DirectQuerywithInMemory' and 'InMemorywithDirectQuery' appear to be gone.
- Sample partitions can be created to be able to see some data inside of the SSDT development environment.
Limitations of DirectQuery in SQL Server 2016:
- In SSAS Tabular, an entire model is either set to Import (In-Memory) or DirectQuery. This is different from SSAS Multidimensional which allows partitions & dimensions to be set individually.
- A single data source is permitted. DirectQuery will not issue cross-database queries.
- Calculated tables are not supported when the model is in DirectQuery mode. The workaround for this is to import a table multiple times (which is what is typically done to handle role-playing dimensions in a Tabular model).
- Not all DAX functions can be translated to SQL syntax, so there are some DAX restrictions. More info is here: https://msdn.microsoft.com/en-us/library/hh213006.aspx.
To take advantage of all of the new improvements, the model must be set to compatibility level 1200.

Finding More Information
MSDN - DirectQuery Mode (SSAS Tabular)
Technical White Paper - Using DirectQuery in the Tabular BI Semantic Model